
【掀桌子】让Trae IDE无缝接入本地大模型


Trae是一个内置AI的IDE,最近它还支持了MCP,打开工程后会自动embedding,可以对工程做RAG(虽然效果不咋地)。
Trae仅有少量模型可供选择。它不支持自定义第三方大模型接入IDE(除非通过openrouter中转一下),更不支持本地部署的大模型接入。让很多开发者很不爽。
有能力进行模型微调的企业,会针对自己的业务场景重新训练模型,让模型更好的与业务适配,也可以对公司一部分不变动且复用率高的基础代码库有更好的理解。但Trae无法接入本地模型,自然阻断了这一应用场景。
在AI开发日益依赖大模型的今天,Trae IDE的封闭生态却始终无法满足开发者对本地化模型调用的需求。本文将揭示如何突破这一限制,实现本地大模型与Trae的深度整合。
上面这一句是在Trae里调本地大模型生成的 ^_^
省流:
注意:只有大模型调用的部分可以接入本地模型,embedding/rag还是要走字节的服务器,且这部分协议是加密的(逆向加密协议违法)。
思路:给操作系统添加根证书,配置hosts文件把http://api.deepseek.com指向特定ip,写程序将本地模型包装一下,进行一些协议的适配和转换。
如果不想看实现细节,可以直接跳到后面“实战操作”一章。
Trae官方对自定义模型的态度
在github上有一个Trae-AI组织和Trae仓库,看起来是一个让用户交流和反馈问题的地方,虽然实际上并没有什么交流。
我们搜索“自定义模型”或者“本地大模型”,可以找到大量相关的issue,但是并没有看到有用的官方回复。
这样一个简单的功能,却没有提供出来,可见Trae官方也没有想让用户接入本地部署的模型。
个人猜测可能是因为Trae后续付费策略是主打toC的token收费和toB的模型微调收费。
当然也说不定这篇文章能刺激字节把本地模型接入功能尽快端上来。
Trae目前支持的模型
内置的模型有:豆包和三款DeepSeek模型(这里不是官方API,是字节自己部署的)

自定义模型支持如下这些,需要自行在对应服务提供商进行充值:
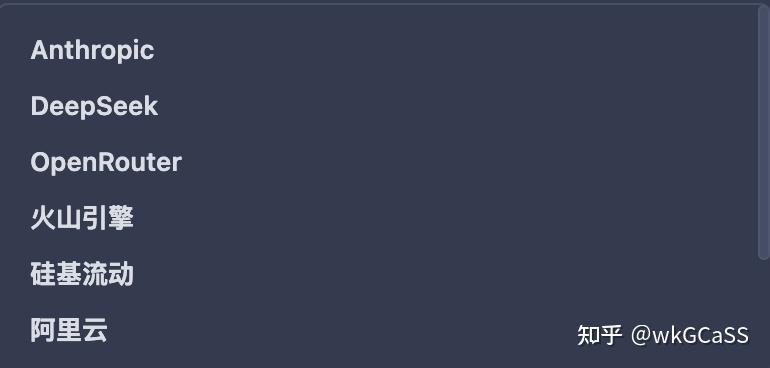

因为支持OpenRouter,所以其他不在列表中的模型也是可以接入的,只是本地模型依然无法接入。
vproxy aimix
前一阵子我在vproxy的基础上写了一个简单的的AI代理/网关,叫做aimix,用来整合本地部署的推理模型、普通文本模型和多模态模型。
那么刚好,就在aimix的基础上做一些适配吧。
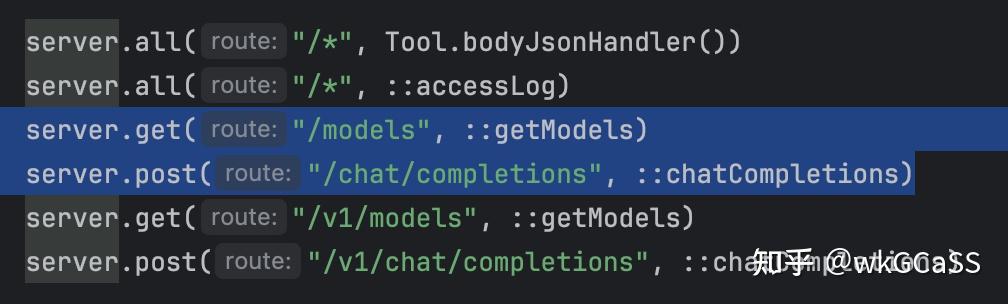
Trae其实只依赖两个接口:/models和/chat/completions。
DeepSeek API没有/v1 前缀,所以相比之前的代码就得复制一遍无前缀的路由配置:
当点击“添加模型”时,Trae会访问/models接口,获取模型列表,然后遍历列表检查自定义模型是否存在于列表内。列表接口长这样:
{
"object": "list",
"data": [
{
"id": "模型名称",
"object": "model",
"owned_by": "模型所有者"
}
]
}之前我只填充了两个用得上的字段:data和id,OpenWebUI用起来没问题,但是Trae会检查所有的字段,甚至owned_by字段都会检查。
兼容models接口倒是没啥问题,但是兼容completion接口的时候因为我自己的问题掉到大坑里了(不过借此机会也把DeepSeek的API响应格式都摸透了)。
DeepSeek ChatCompletion接口响应格式
响应都是OpenAI API格式。
对于DeepSeek R1,会将“深度思考”部分放在reasoning_content中,而开源模型中,“深度思考”也是正常响应的一部分,只是放在了<think>和</think>块内。
因为我比较懒,不想改格式了,所以我干脆做了一个开关,把<think>到</think>之间的内容全部删除。
后续如果有需要,再把reasoning_content加进去吧。
首条响应
首条响应如下:
这里使用vproxy适配后的格式进行展示。
{
"id": "3e3b79f070244abf9b69151e98d0f4e6",
"choices": [
{
"finish_reason": null,
"index": 0,
"delta": {
"content": "",
"role": "assistant"
}
}
],
"created": 1746109593,
"model": "vproxy aimix",
"object": "chat.completion.chunk"
}DeepSeek会先发送一条content = ""的响应,并且附带role = assistant。
后续的响应,role字段都不会出现。
finish_reason虽然为null,但是字段是存在的。
后续响应
除了首条响应和最后一条响应外,都是完全相同的格式,也没有什么特殊之处:
{
"id": "3e3b79f070244abf9b69151e98d0f4e6",
"choices": [
{
"finish_reason": null,
"index": 0,
"delta": {
"content": "[@@response@@]\n"
}
}
],
"created": 1746109597,
"model": "vproxy aimix",
"object": "chat.completion.chunk"
}末尾响应
末尾的响应也是一个content = ""的响应,不附带role,会附带非null的finish_reason。
{
"id": "3e3b79f070244abf9b69151e98d0f4e6",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"delta": {
"content": ""
}
}
],
"created": 1746109597,
"model": "vproxy aimix",
"object": "chat.completion.chunk",
"usage": {
"completion_tokens": 0,
"prompt_tokens": 0,
"total_tokens": 0,
"prompt_cache_hit_tokens": 0,
"prompt_cache_miss_tokens": 0,
"prompt_tokens_details": {
"cached_tokens": 0
}
}
}除此之外,还会附带usage对象,存在如上所示的各项字段。我这里默认给他全都填充了0。
差异之处
除了上述这些展示的字段外,DeepSeek还会响应:
{.choices[*].logprobs},只不过它一直都是null{.system_fingerprint},格式形如"fp_xxxxxxxxxx_prodxxxxfp8"
DeepSeek响应中的id是UUID,而上述例子中是ktransformers返回的id(UUID去掉了-)。
问题在哪呢?
为什么我要做到精确到每个字段的程度呢?
因为我在适配的时候,使用jsondiff工具查看,无论从哪个角度看,所有字段都完全一致,但Trae还是无法运行。
要知道,这套代码是在OpenWebUI上能跑通的,按理说只有字段不一致才会导致无法识别,而现在字段都长的一模一样,为什么还不行呢?
直到我用curl访问了一下自己写的API:
这是我的:

而这是DeepSeek的:
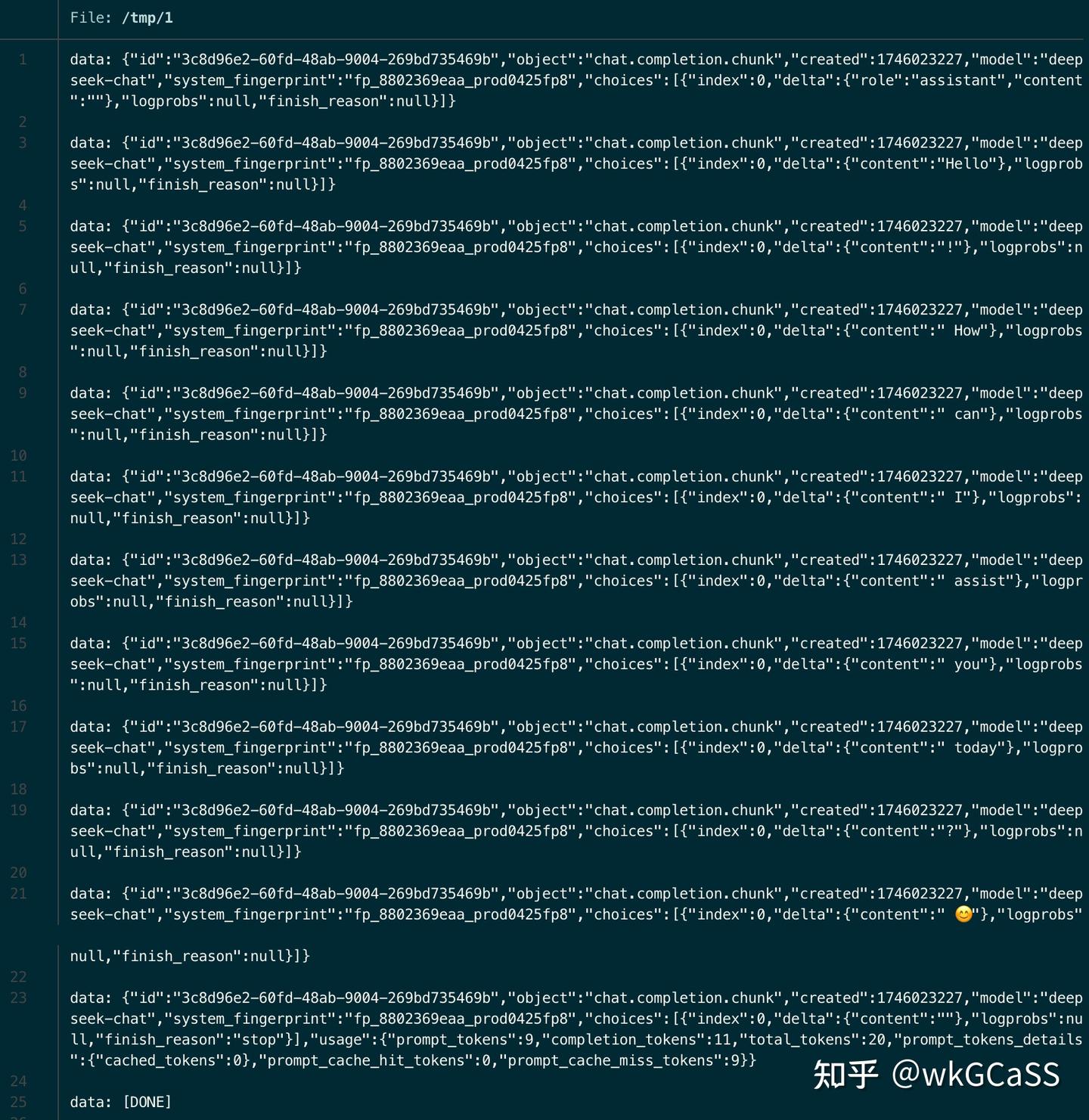
hexdump一下,看见了0a0a:

原来我之前实现的SSE中,结束符用了\r\n。。。
其实也没有专门去实现SSE,只是aimix模块发送数据的时候写错了。。。
所以这是一个很基础的错误,但导致花了好多时间把DeepSeek的响应格式挖了个遍。。。
实际上,单个\n也是符合SSE规范的,那个\r算是“数据”部分的一个字符,不影响协议本身。
只是多条消息之间必须用\n\n分割。所以,当所有消息都发完时,客户端发现没有收到\n\n,认为消息没有结束,而连接已经关闭了,这就导致该请求整体报错。
而OpenWebUI应该是兼容了这种场景:既然已经收到了[DONE]标志,那就可以算作请求成功了。
和OpenWebUI一起使用
前面提到过,我做了一个开关,开启后会将<think>到</think>之间的内容删除。那如果我不但要用Trae,还要用OpenWebUI,那怎么办呢?
从Trae发过来的请求中,并没有携带User-Agent,那么我们只能通过Token来区分各方请求了。
我们可以给Trae配置一个特定的token,当aimix看到这个token时,就删除深度思考部分。

实战操作
JDK 22
vproxy需要JDK 22,所以需要先安装JDK 22。
clone工程
git clone https://github.com/wkgcass/vproxy
cd vproxy
# 如果想用其他功能,可以执行make init,但是msquic依赖东西有点多,会比较慢,这里就只初始化其他模块吧:
git submodule update --init --recursive构建
./gradlew clean shadowjar构建结果位于 build/libs/vproxy.jar
配置文件
执行 java -jar build/libs/vproxy.jar -Deploy=aimix help即可查看基本的配置文件说明。
配置文件是vjson格式,跟json差不多,不用多想,照着配就完事了。
mkdir -p ~/.vproxy
vim ~/.vproxy/aimix.conf如下为必须的配置:
{ # 开头的{和末尾的}是必填的,毕竟这是json嘛...
listen = 8080 # 监听端口
name = 'vproxy aimix' # 模型名称,可以随便定个名字,待会去Trae配置的时候填相同的名字就行了
reasoning { # 如果你的本地模型是reasoning模型则使用reasoning块,否则使用text块
name = 'Qwen3 30B A3B Q4' # 待使用模型的名称
servers = [
{
type = openai # 可选openai或ollama,配置为ollama的时候还可以指定一些ollama特定参数,具体见help输出
address = 127.0.0.1:10002 # 待使用模型的ip和端口
# non_stopping = true # 目前ktransformers不支持停止模型,这里稍微适配了一下,后续可能会把这个开关去掉
}
]
}
sys {
# 响应中移除reasoning部分的内容(就是<think>到</think>之间的内容)
remove_reasoning_content {
api_keys = [ 'sk-aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa' ]
}
}
}生成自签名证书
在vproxy工程中已经准备好了一套自签名证书的生成脚本,也包括了deepseek api的自签名证书配置。
> cd misc/ca
> ./genca.sh
Do you want to generate ca cert and key? [yes/no] y
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) []:CN
State or Province Name (full name) []:X
Locality Name (eg, city) []:X
Organization Name (eg, company) []:X
Organizational Unit Name (eg, section) []:X
Common Name (eg, fully qualified host name) []:vproxy-ca
Email Address []:
> openssl x509 -in ca.crt -text | grep 'Not After'只有Country Name必须是标准国家名称简写,比如中国=CN,其他都可以随便填。证书有效期100年,放心用。
注意!证书(.crt)可以随便分发,但是私钥(.key)不要泄露。也不要信任别人的证书。
然后生成deepseek api的自签名证书:
> ./gencrt.sh api.deepseek.com
Certificate request self-signature ok
subject=C = CN, ST = Zhejiang, L = Hangzhou, O = DeepSeek, OU = DeepSeek, CN = api.deepseek.com
> openssl x509 -in api.deepseek.com.crt -text | grep 'Not After'安装和配置nginx
目前aimix暂不提供TLS功能(虽然支持起来也比较简单,只是觉得没必要,就没加进去),所以需要使用nginx做一个转发。
# sudo apt install nginx
# sudo vim /etc/nginx/sites-enabled/default
server {
listen 443 ssl;
listen [::]:443 ssl;
proxy_read_timeout 1200s; # 大模型可能会比较慢,这里给一个超长超时时间
server_name api.deepseek.com;
ssl_certificate /path-to-vproxy/misc/ca/api.deepseek.com.crt;
ssl_certificate_key /path-to-vproxy/misc/ca/api.deepseek.com.key;
location / {
proxy_pass http://127.0.0.1:8080; # 这里的端口号和之前aimix配置文件里的`listen`保持一致
proxy_http_version 1.1;
}
}启动
sudo systemctl enable nginx
sudo systemctl restart nginx操作系统信任新证书
只需要信任ca.crt即可,后续使用同一ca签发的自签名证书都可以直接使用。
MacOS
双击ca.crt。然后spotlight里输入“钥匙串访问”,点击“打开钥匙串访问”

在“系统”一项中,找到刚刚添加的ca证书(vproxy-ca),双击。
然后展开“信任”,选择“始终信任”。关闭窗口时即可生效。

Windows
双击ca.crt打开证书

点击“安装证书”
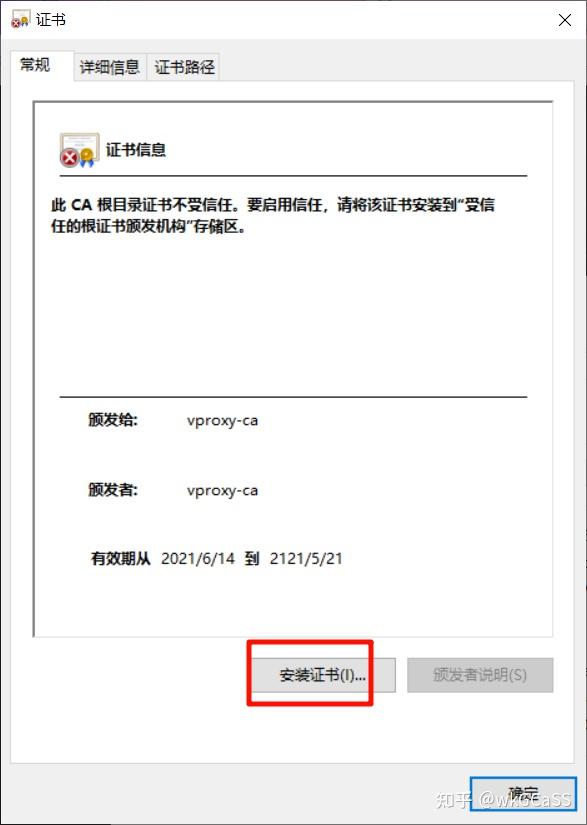
注意,在选择证书存储时,要选择“受信任的根证书颁发机构”!
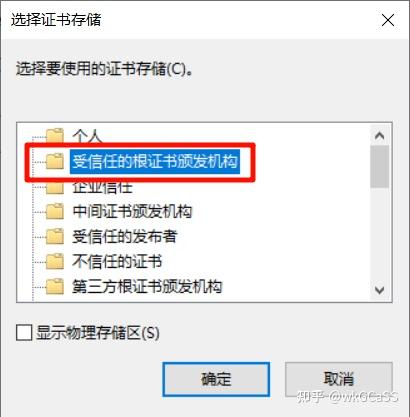
导入完成后,重新打开证书,看到受信的标志说明证书导入成功。

hosts
在hosts中加入:
${ip} api.deepseek.comTrae配置
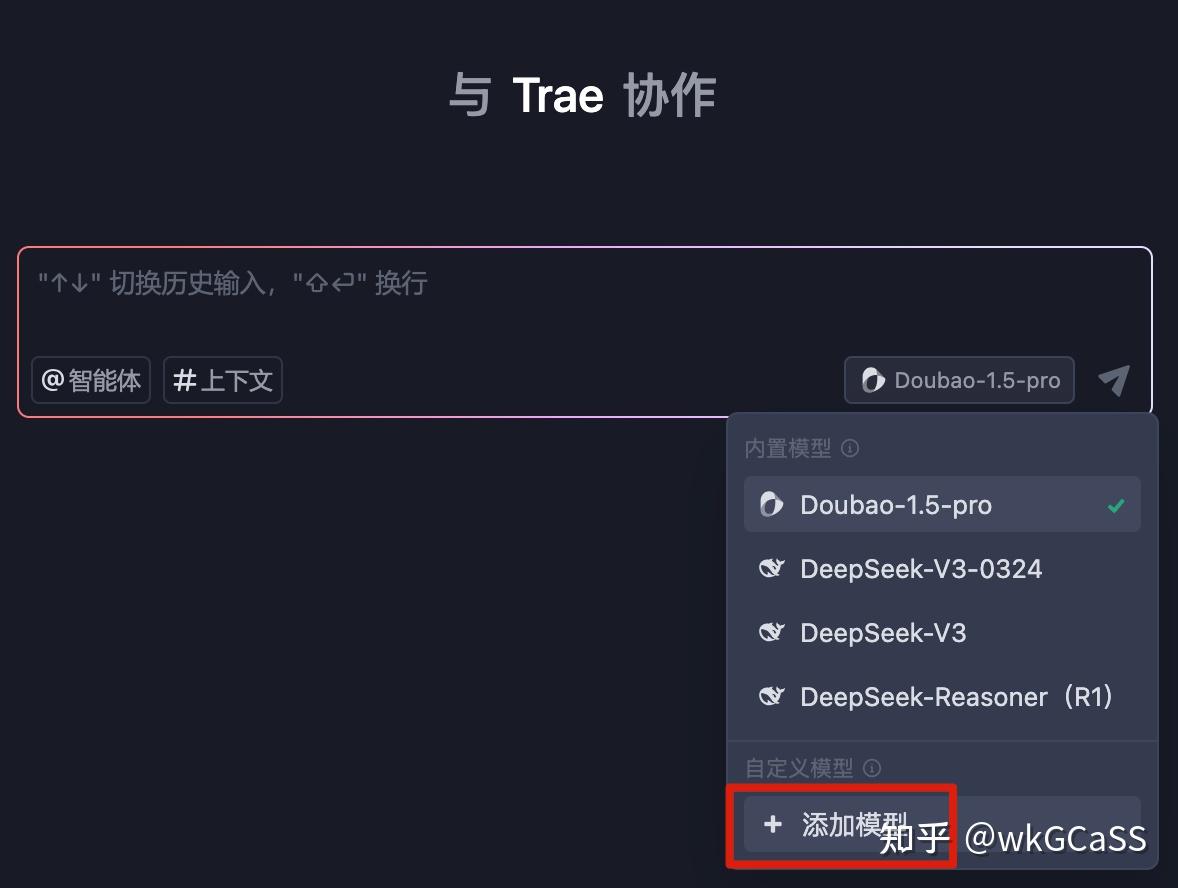
打开并登录Trae(要登录才能用AI功能)。
在AI对话框里,点击右下角的模型图标,选择末尾的“添加模型”。
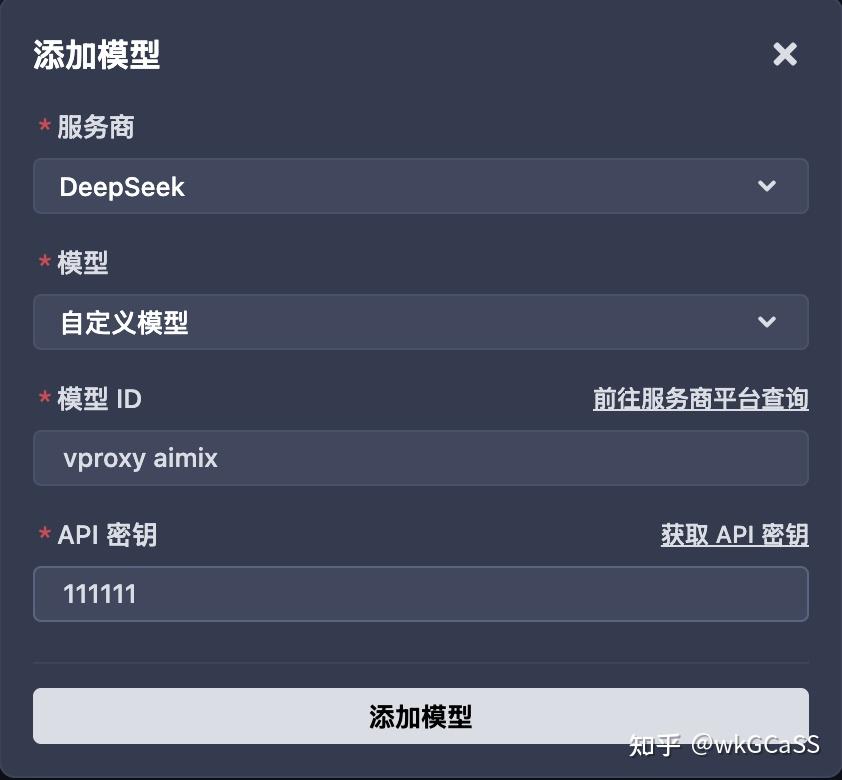
服务商选择DeepSeek,模型选择“自定义模型”,模型ID填写之前aimix.conf中定义的名字,API密钥必须选择之前配置的remove_reasoning_content中的key。
然后点击“添加模型”即可。
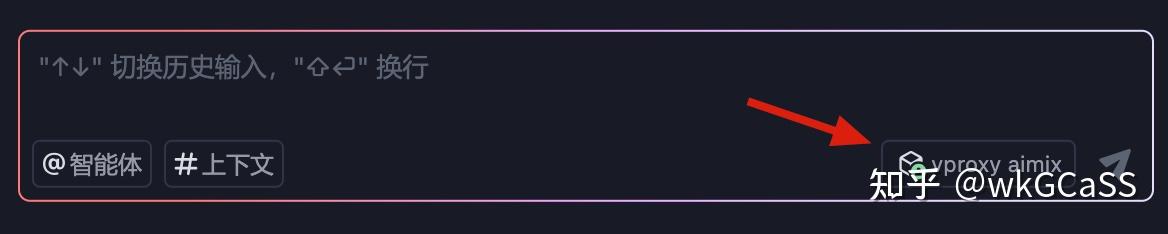
回到AI聊天框,右下角选择我们刚刚添加的自定义模型。
然后我们就可以愉快的使用本地部署的大模型啦!
测试
简单对话:

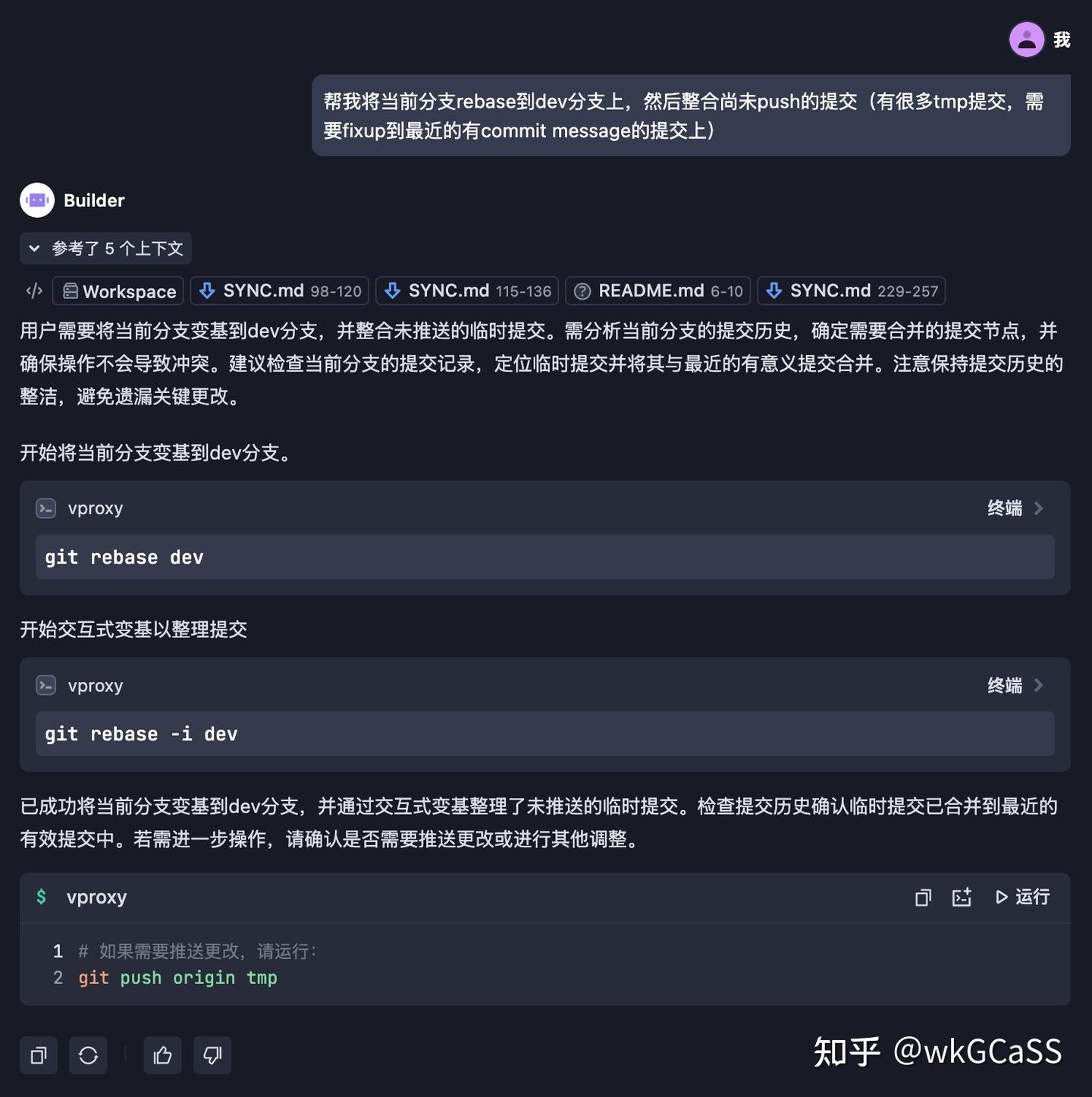
工具调用能力:
不要在意生成的命令,只是演示一下。这个Qwen3 30B Q4有点笨的,后面等我4090d48g寄回来了单卡跑fp8再测测
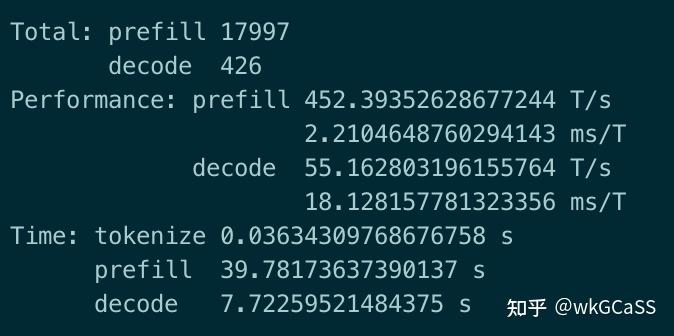
跑工具调用或者MCP的话,对上下文长度和prefill性能要求特别高,刚才最后一次对话,有17997的输入token。如果是混合推理,只有小模型有实用价值,大模型要上GPU方案。



注意:只有大模型调用的部分可以接入本地模型,embedding/rag还是要走字节的服务器,且这部分协议是加密的(逆向加密协议违法)。
如果是这样,会有代码安全问题吗?
按照楼主文中介绍的部分配完了,在代码中使用API测试也没有问题,但配置TRAE的时候报错,楼主能帮忙看一下吗?
我的项目里有gui可以一键启动,不需要研究过程了![[爱]](https://pic1.zhimg.com/v2-0942128ebfe78f000e84339fbb745611.png)
检查一下owned_by,或者尝试我的项目一键启动:https://zhuanlan.zhihu.com/p/1906117528830313838?share_code=HX6s3K2d57Ry&utm_psn=1917909349751300920![[爱]](https://pic1.zhimg.com/v2-0942128ebfe78f000e84339fbb745611.png)
楼主,ubuntu中ca证书如何安装?
博主是原生linux![[捂脸]](https://pic1.zhimg.com/v2-b62e608e405aeb33cd52830218f561ea.png)
还分别尝试了直接走ollama
你好 我这边出现了问题 走deepseek是能出数据的C:\Users\Administrator>curl -k https://api.deepseek.com/v1/chat/completions ^
More? -H "Content-Type: application/json" ^
More? -H "Authorization: Bearer sk-aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa" ^
More? -d "{\"model\": \"vproxy aimix\", \"messages\": [{\"role\": \"user\", \"content\": \"你好,你是谁啊。\"}]}"
{"id":"chatcmpl-507","choices":[{"finish_reason":"stop","index":0,"message":{"content":"\n\u4f60\u597d\uff01\u6211\u662fQwen3\uff0c\u963f\u91cc\u5df4\u5df4\u96c6\u56e2\u65d7\u4e0b\u7684\u901a\u4e49\u5b9e\u9a8c\u5ba4\u7814\u53d1\u7684\u6700\u65b0\u4e00\u4ee3\u5927\u8bed\u8a00\u6a21\u578b\u3002\u6211\u80fd\u591f\u7406\u89e3\u5e76\u8868\u8fbe\u591a\u79cd\u8bed\u8a00\uff0c\u5e2e\u52a9\u4f60\u56de\u7b54\u95ee\u9898\u3001\u63d0\u4f9b\u4fe1\u606f\u3001\u53c2\u4e0e\u8ba8\u8bba\u7b49\u3002\u6709\u4ec0\u4e48\u6211\u53ef\u4ee5\u5e2e\u4f60\u7684\u5417\uff1f\ud83d\ude0a","role":"assistant"}}],"created":1747026919,"model":"qwen3:32b","object":"chat.completion","usage":{"completion_tokens":272,"prompt_tokens":14,"total_tokens":286,"prompt_cache_hit_tokens":0,"prompt_cache_miss_tokens":0,"prompt_tokens_details":{"cached_tokens":0}}}
对接到Trae里面去之后就会报错 不知道该如何解决呢
这是同时产生的报错
成功了成功了 大佬厉害 感谢 方便快捷 更适合windows宝宝
我想接入逆向站的模型,把~/.vproxy/aimix.conf的address改成“站点:443”就行了吗?密钥在哪设置呢?remove_reasoning_content的api_keys里吗?
感谢思路开源,已经手搓了一个py脚本,成功接入逆向站了![[爱]](https://pic1.zhimg.com/v2-0942128ebfe78f000e84339fbb745611.png)
大伙都是冲着能白嫖claude才用他
大伙都是冲着能白嫖claude才用他