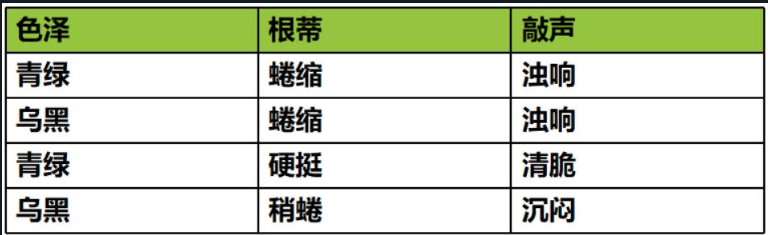
我们把数据中的每一行称为一个示例或样本;
反映事件或对象在某方面的表现或性质的事项,如:色泽、根蒂、敲声,称为属性或特征;
属性上的取值,例如:青绿、乌黑。称为属性值或特征值;
我们把一个示例(样本)的所有特征值称为一个特征向量。
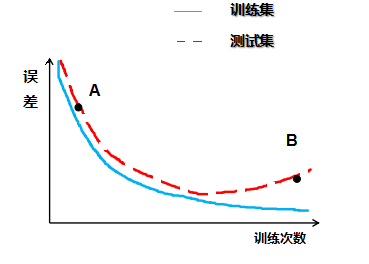
不断增加训练强度减小训练误差到一定程度后,继续减小训练误差可能导致泛化误差上升,称为“过拟合”
一般不能将测试样本用于对模型的训练,测试样本参与训练称为“样本泄露”,通俗的说就是“漏题了”
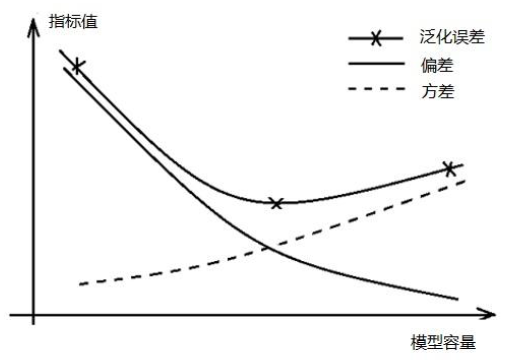
模型容量(模型复杂度)表示模型能拟合的输入到输出的映射关系的多少的能力。比如模型y=ax^2+bx+c的容量大于模型y=bx+c。模型容量大的直观表现为,模型的参数数目多或参数的取值范围大,模型容量与方差、偏差和泛化误差的关系如下图,模型容量(模型复杂度)太高将导致过拟合,即训练误差底但泛化误差高。
对于不平衡样本(正类与负类比例相差很大),仅用正确率或错误率评估是不全面的。如对癌症病人的判断,假设只有不到10%的人患有癌症,将全部病人都判为健康也有大于90%的正确率。这种情况下我们更关其中某个类别的统计指标的好坏,我们把关心的类别如“有癌症”设为正类,用召回率、精准率、F1、ROC、AUC等指标评价模型在这个关注的分类上的性能。
查全率和查准率不可能同时最优,评估模型(选择模型)用查全率还是查准率是根据具体业务的需要,是更看重不要漏判还是不要错判。比如判断癌症病人时追求不要漏判,判断股票是否会涨时追求不要错判。在不清楚业务目标的情况下就使用综合指标F1或AUC来评估。
AUC是计算ROC曲线下的面积得来的,而ROC曲线是调节模型的判断阈值绘制出来的,因此AUC值不能用F1值直接换算出来。
答案D所用的样本划分法就是K折交叉验证
1.样本数量较少时用自助法构造测试集和训练集更合适
2.另外一种采用自助法的情况是,bagging集成学习,通过自助随机采样构造训练样本子集训练出多个具有一定差异的弱学习器,再将这些弱学习器集成为一个具有较强泛化性的强学习器。
原始的数据不同维度的特征值可能因为单位的不同其数值的取值范围有很大的差异,有些模型对特征值的大小异常敏感(如SVM,神经网络,k-means),不同维度特征值间数量级的差异将显著影响模型的效果和求解速度,所以要将所有不同维度的特征值缩放到相同的取值范围,特征值的标准化(归一化)缩放方法常用的有:
Z-score缩放,公式:
Min-Max缩放,公式:
MaxAbs缩放,公式:
等
某些模型的输入必须是数字,所以要将分类特征编码为数字后输入给模型。One-Hot码又称为N取一码,其思想是将一个分类特征变换为多个新特征(新特征数量和类别数相同),如原颜色特征有“红”,“黄”,“蓝”三种取值。转换为One-Hot码后用“红”,“黄”,“蓝”三个新特征表示,是哪种颜色对应特征值为1,其它特征值为0,如颜色为“红”色的新特征值为100。如果不同的类别简单地用整数编码如1,2,3表示,则可能让模型潜在地学习到黄色比红色大,而实际上不同的颜色地位是平等的。但如果分类本身含有有等级信息如“星级评价”,则更适合用整数编码。
生成多项特征可以有效提升模型的复杂度,以二维特征(,
)为例,生成二阶多项式特征后转化为(
,
,
,
,
,
), 将转化后的特征向量输入给线性回归模型学习就是多项式回归模型,而且还引入了非线性关系和特征间的交互关系。
模型结构:确定模型映射函数的基本结构
目标函数:根据数据和模型特点,确定合适的模型优化目标,构造模型优化的目标函数
优化算法:用合适的算法对目标函数最优化,求解模型参数
根据下面的某个分类任务模型预测结果的混淆矩阵,计算查准率P(f)_______、查全率W(f)_________及F1分数_______,结果以小数表示精确到小数点后3位。
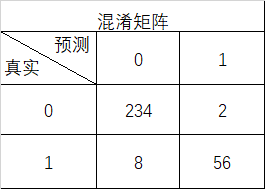
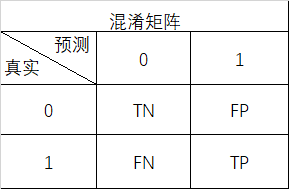
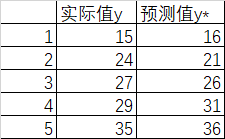
根据下面的某个回归任务模型的预测值与实际值数据,计算模型评估的R2分数,结果精确到小数点后3位,R2=_________。