
TL;DR
Deep research has broken out as one of the most popular agent applications. OpenAI, Anthropic, Perplexity, and Google all have deep research products that produce comprehensive reports using various sources of context. There are also many open source implementations.
深度研究已成为最受欢迎的智能体应用之一。OpenAI、Anthropic、Perplexity 和 Google 都推出了深度研究产品,这些产品能利用各种来源的上下文生成综合报告。此外,还有许多开源实现。
We've built an open deep researcher that is simple and configurable, allowing users to bring their own models, search tools, and MCP servers.
我们构建了一个开放式的深度研究工具,它简单且可配置,允许用户引入自己的模型、搜索工具和 MCP 服务器。
- Open deep research is built on LangGraph. See the code here!
开放式深度研究基于 LangGraph 构建。查看代码! - Try it out on Open Agent Platform
在 Open Agent 平台上试试
Challenge 挑战
Research is an open‑ended task; the best strategy to answer a user request can’t be easily known in advance. Requests can require different research strategies and varying levels of search depth.
研究是一个开放的任务;要回答用户请求的最佳策略并不能轻易提前知道。请求可能需要不同的研究策略和不同深度的搜索。
“Compare these two products”
“比较这两个产品”
Comparisons typically benefit from a search on each product, followed by a synthesis step to compare them.
比较通常受益于对每个产品进行搜索,然后进行综合步骤来比较它们。
“Find the top 20 candidates for this role”
“找出这个职位的 20 个最佳候选人”
Listing and ranking requests typically require open-ended search, followed by a synthesis and ranking.
列表和排名请求通常需要开放式搜索,然后进行综合和排名。
“Is X really true?” “X 真的正确吗?”
Validation questions can require iterative deep research into a specific domain, where the quality of sources matters much more than the breadth of the search.
验证性问题可能需要针对特定领域进行迭代式深入研究,此时信息来源的质量比搜索的广度更为重要。
With these points in mind, a key design principle for open deep research is flexibility to explore different research strategies depending on the request.
考虑到这些要点,开放式深入研究的一个关键设计原则是灵活地根据请求探索不同的研究策略。
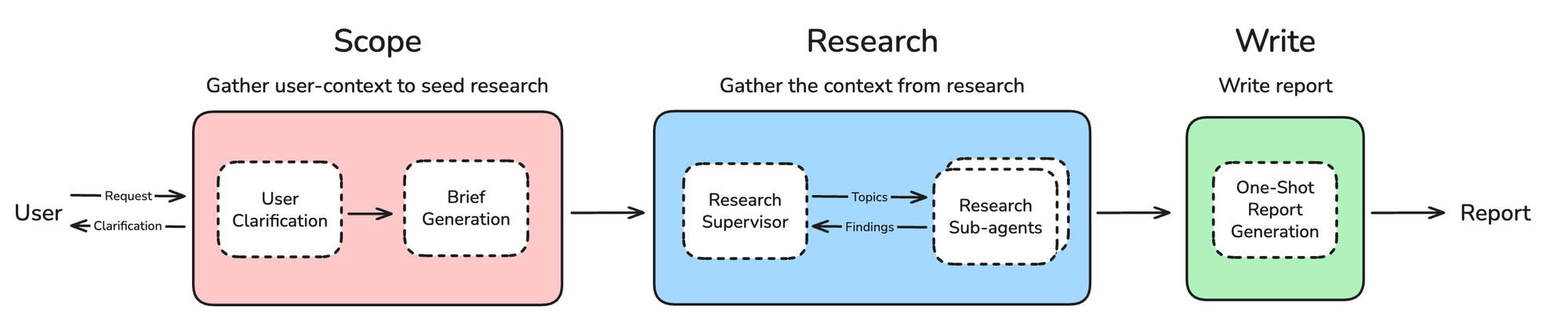
Architectural Overview 架构概述
Agents are well suited to research because they can flexibly apply different strategies, using intermediate results to guide their exploration. Open deep research uses an agent to conduct research as part of a three step process:
智能体非常适合进行研究,因为它们可以灵活地应用不同的策略,并利用中间结果来指导其探索。开放式深入研究使用一个智能体作为三步流程中的一部分来执行研究:
- Scope – clarify research scope
范围 – 明确研究范围 - Research – perform research
研究 – 进行研究 - Write – produce the final report
撰写 – 完成最终报告
Phase 1: Scope 第一阶段:范围
The purpose of scoping is to gather all user-context needed for research. This is a two-step pipeline that performs User Clarification and Brief Generation.
界定范围的目的在于收集研究所需的所有用户背景信息。这是一个包含用户澄清和简报生成的两步流程。
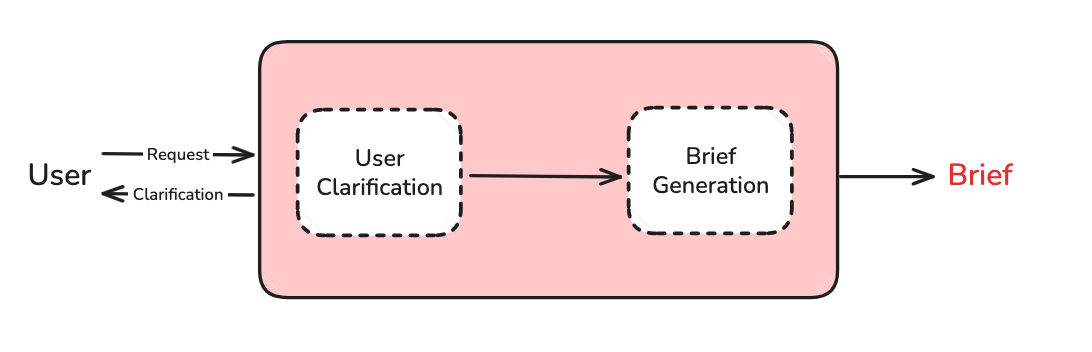
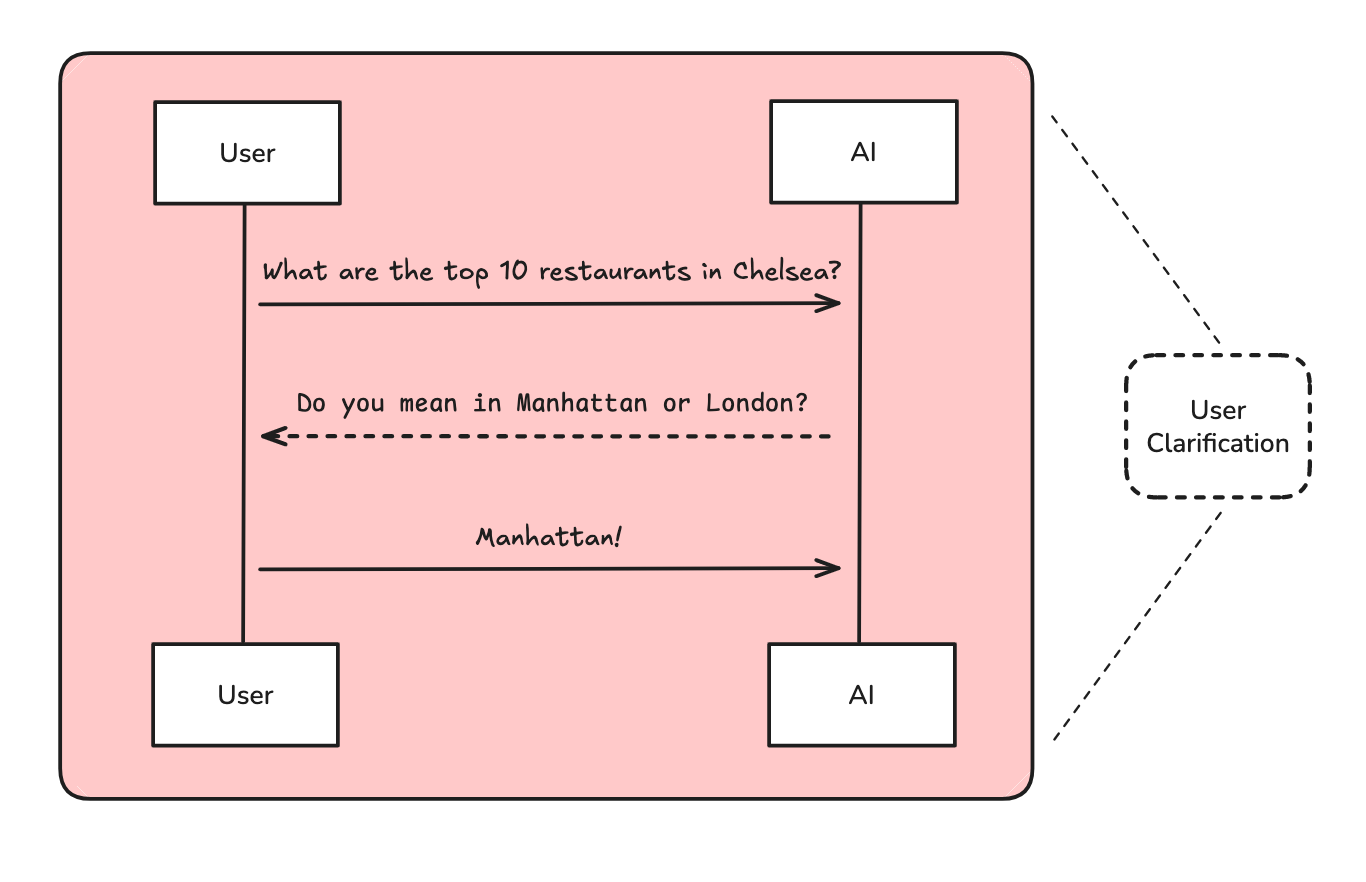
User Clarification 用户说明
OpenAI has made the point that users rarely provide sufficient context in a research request. We use a chat model to ask for additional context if necessary.
OpenAI 指出,用户在研究请求中很少提供足够的背景信息。如果需要,我们使用聊天模型来请求额外的背景信息。
Brief Generation 简要生成
The chat interaction can include clarification questions, follow-ups, or user-provided examples (e.g., a prior deep research report). Because the interaction can be quite verbose and token-heavy, we translate it into a comprehensive, yet focused research brief.
聊天交互可以包括澄清问题、后续问题或用户提供的示例(例如,先前的深度研究报告)。由于交互可能非常冗长且包含大量 token,我们将它翻译成一份全面但重点突出的研究简要。
The research brief serves as our north star for success, and we refer back to it throughout the research and writing phases.
研究简要是我们成功的指南针,我们在研究和写作阶段都会参考它。
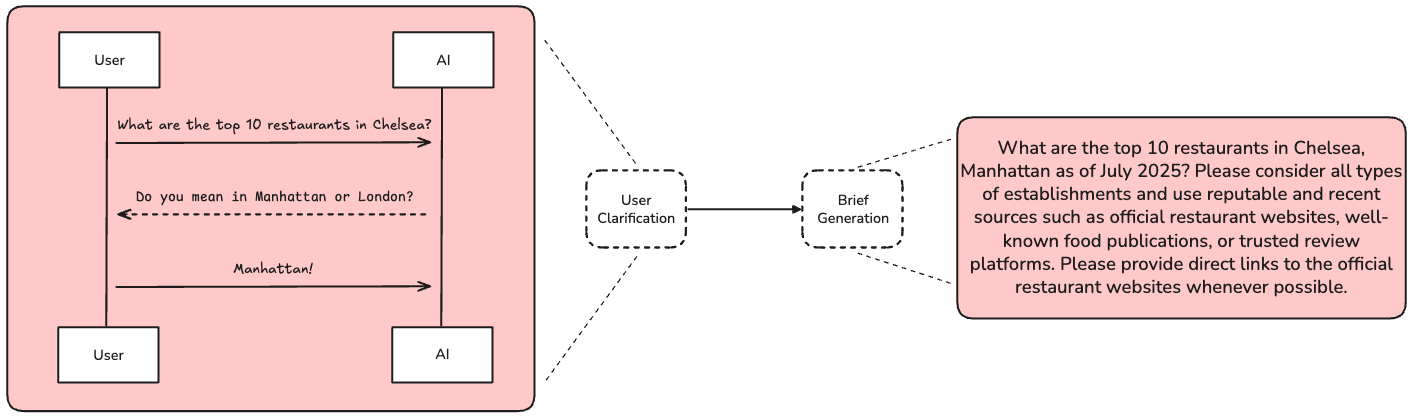
我们将研究者-用户聊天互动转化为一份聚焦的简报,供研究导师参考衡量。
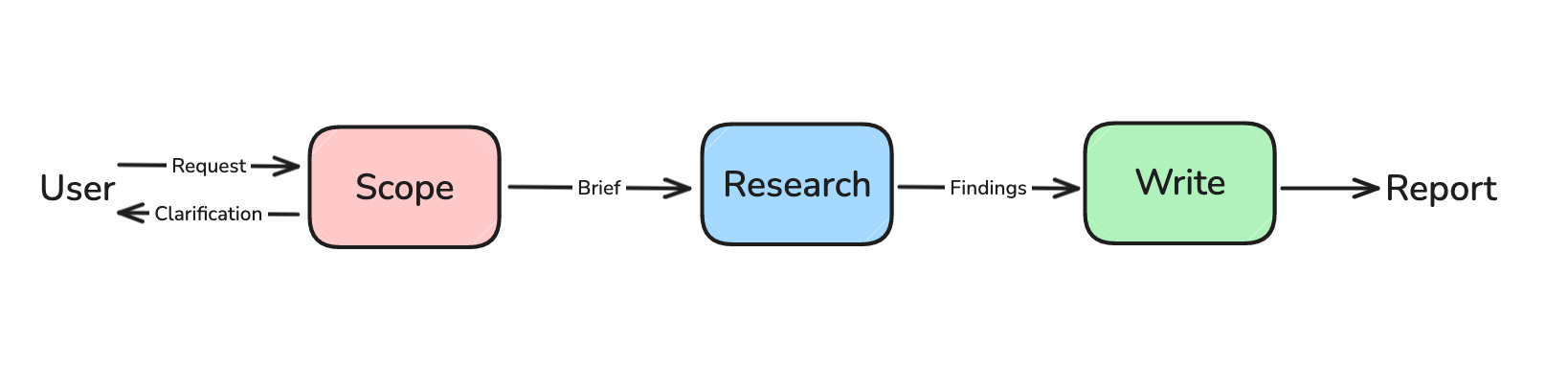
Phase 2: Research 第二阶段:研究
The goal of research is to gather the context requested by the research brief. We conduct research using a supervisor agent.
研究的目标是收集研究简报中要求的背景信息。我们使用监督代理进行研究。
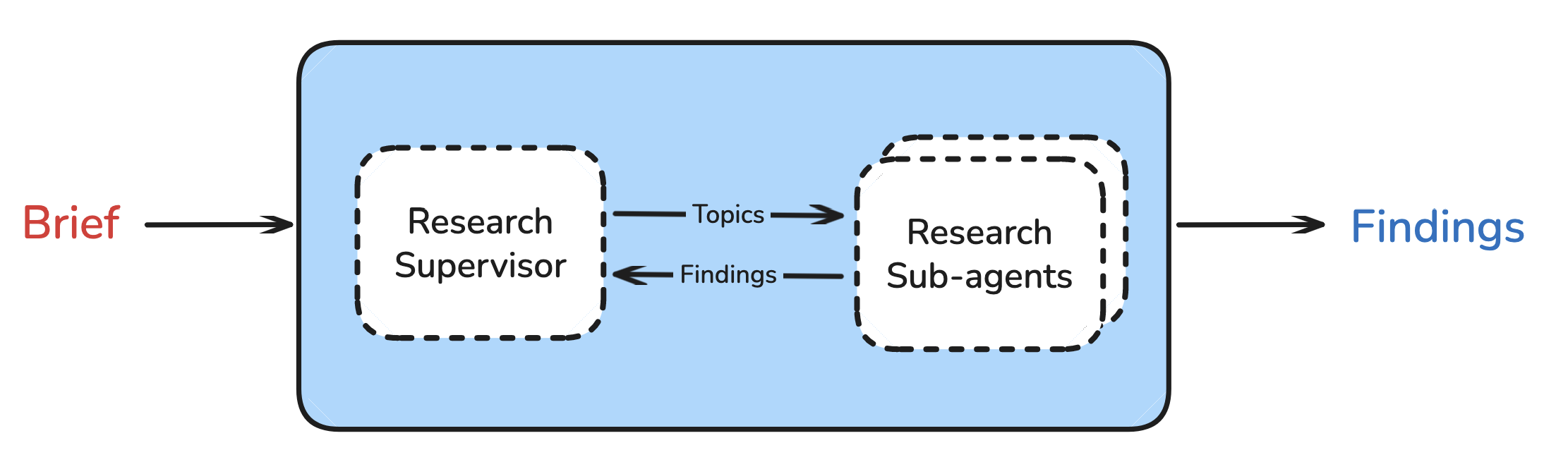
Research Supervisor 研究导师
The supervisor has a simple job: delegate research tasks to an appropriate number of sub-agents. The supervisor determines if the research brief can be broken-down into independent sub-topics and delegates to sub-agents with isolated context windows.
主管的工作很简单:将研究任务分配给适当数量的子代理。主管确定研究简报是否可以分解为独立子主题,并分配给具有隔离上下文窗口的子代理。
This is useful because it allows the system to parallelize research work, finding more information faster.
这样做很有用,因为它允许系统并行化研究工作,更快地获取更多信息。
Research Sub-Agents 研究子代理
Each research sub-agent is presented with a sub-topic from the supervisor. The sub-agent is prompted to focus only on a specific topic and doesn’t worry about the full scope of research brief – that's a job for the supervisor.
每个研究子代理会从主管那里获得一个子主题。子代理被提示只关注特定主题,而不用担心研究简报的完整范围——那是主管的工作。
Each sub-agent conducts research as a tool-calling loop, making use of search tools and / or MCP tools configured by the user.
每个子代理以工具调用循环的方式进行研究,利用用户配置的搜索工具和/或 MCP 工具。
When each sub-agent finishes, it makes a final LLM call to write a detailed answer to the subquestion posed, taking into account all of its research and citing helpful sources.
当每个子代理完成时,它会进行最终的 LLM 调用,以撰写对所提出子问题的详细答案,并考虑到其所有研究内容,并引用有帮助的来源。
This is important because there can be a lot of raw (e.g. scraped web pages) and irrelevant (e.g. failed tool calls, or irrelevant web sites) information collected from tool call feedback.
这很重要,因为从工具调用反馈中收集到的信息可能有很多原始信息(例如,抓取的网页)和不相关的信息(例如,失败的工具调用或不相关的网站)。
我们进行额外的 LLM 调用以清理子代理研究发现的,以便向监督者提供干净、已处理的信息。
If we return this raw information to the supervisor, the token usage can bloat significantly and the supervisor is forced parse through more tokens in order to isolate the most useful information. So, our sub-agent cleans up its findings and returns them to the supervisor.
如果我们把原始信息返回给监督者,token 使用量会显著增加,监督者被迫解析更多的 token 才能提取最有用的信息。因此,我们的子代理会整理其发现并返回给监督者。
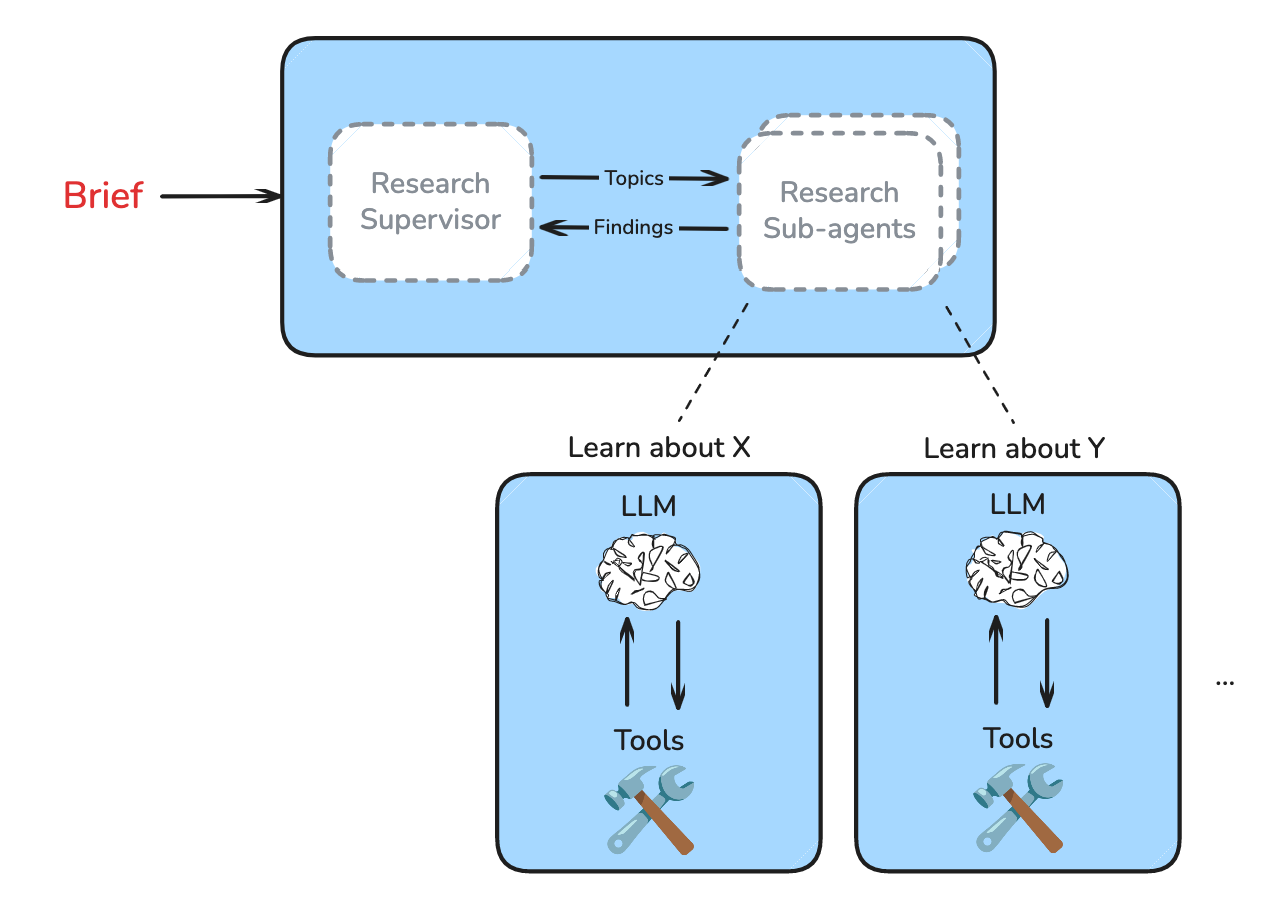
Research Supervisor Iteration
研究导师迭代
The supervisor reasons about whether the findings from the sub-agents sufficiently address the scope of work in the brief. If the supervisor wants more depth, it can spawn further sub-agents to conduct more research.
导师思考子代理人的研究结果是否充分覆盖了简报中规定的工作范围。如果导师希望更深入的研究,可以生成更多的子代理人来开展进一步研究。
As the supervisor delegates research and reflects on results, it can flexibly identify what is missing and address these gaps with follow-up research.
随着导师分配研究和反思结果,它可以灵活地识别缺失的内容,并通过后续研究来弥补这些差距。
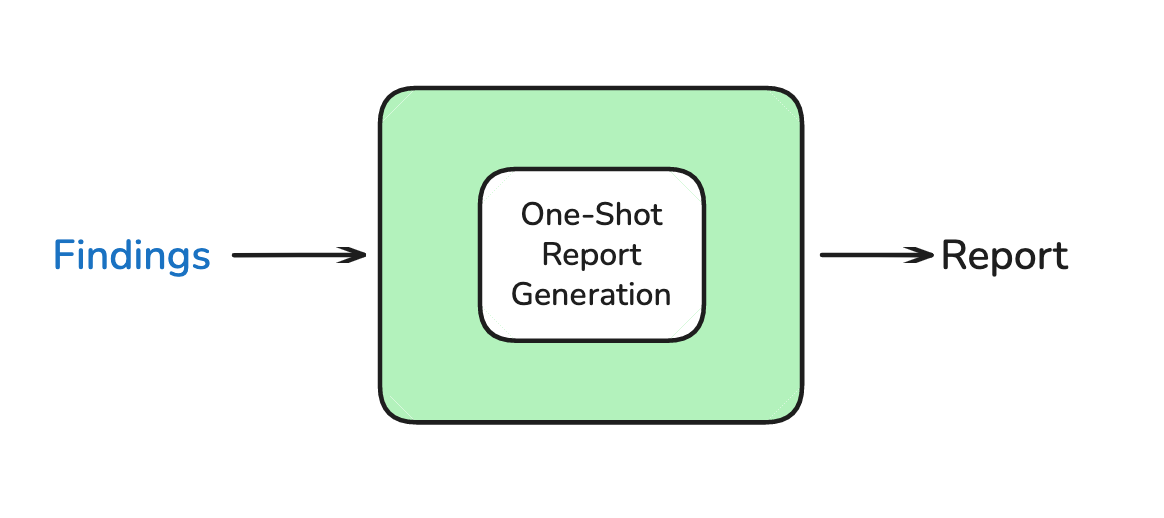
Phase 3: Report Writing 第三阶段:报告撰写
The goal of report writing is to fulfill the request in the research brief using the gathered context from sub-agents. When the supervisor deems that the gathered findings are sufficient to address the request in the research brief, then we move ahead to write the report.
撰写报告的目标是利用从子代理那里收集到的背景信息来满足研究简报中的请求。当主管认为收集到的发现足以解决研究简报中的请求时,我们便开始撰写报告。
To write the report, we provide an LLM with the research brief and all of the research findings returned by sub-agents. This final LLM call produces an output in one-shot, steered by the brief and answered with the research findings.
为了撰写报告,我们将研究简报和子代理返回的所有研究发现在一起提供给一个 LLM。这次最终的 LLM 调用将产生一个单次的输出,由简报引导,并用研究发现来回答。
Lessons 教训
Only use multi-agent for easily parallelized tasks
仅对易于并行处理的任务使用多智能体
Multi vs. single-agent is an important design consideration. Cognition has argued against multi-agent because sub-agents working in parallel can be difficult to coordinate. If the task (e.g., building an application) requires the multi-agent outputs to function together, then coordination is a risk.
多智能体与单智能体是重要的设计考量。Cognition 曾反对使用多智能体,因为并行工作的子智能体难以协调。如果任务(例如,构建应用程序)需要多智能体输出协同工作,那么协调就是一个风险。
We also learned this lesson. Earlier versions of our research agent wrote sections of the final report in parallel with sub-agents. It was fast, but we faced a problem that Cognition raised: the reports were disjoint because the section-writing agents were not well coordinated.
我们也学到了这个教训。我们研究代理的早期版本在并行使用子智能体撰写最终报告的各个部分。这很快,但我们遇到了 Cognition 提出的问题:报告内容不连贯,因为负责撰写各部分的智能体之间协调不佳。
We resolved this by using multi-agent for only the research task itself, performing writing after all research was done.
我们通过仅使用多智能体处理研究任务本身,并在所有研究完成后进行写作来解决这一问题。
多智能体难以协调,如果并行编写报告的各个部分,可能会表现不佳。我们将多智能体限制在研究上,并一次性完成报告的编写。
Multi-agent is useful for isolating context across sub-research topics
多智能体机制有助于隔离不同子研究主题的上下文
Our experiments showed that single agent response quality suffers if the request has multiple sub-topics (e.g., compare A to B to C). The intuition here is straightforward: a single context window needs to store and reason about tool feedback across all of the sub-topics.
我们的实验表明,如果请求包含多个子主题(例如,比较 A 与 B 与 C),单个智能体的响应质量会下降。这里的直觉很直接:单个上下文窗口需要存储和推理跨越所有子主题的工具反馈。
This tool feedback is often token heavy. Numerous failure modes, such as context clash, become prevalent as the context window accumulates tool calls across many different sub-topics.
这种工具反馈通常包含大量 token。随着上下文窗口积累来自许多不同子主题的工具调用,会出现多种失败模式,如上下文冲突,这些问题会变得普遍。
Let’s look at a concrete example
让我们来看一个具体的例子
Compare the approaches of OpenAI vs Anthropic vs Google DeepMind to AI safety. I want to understand their different philosophical frameworks, research priorities, and how they're thinking about the alignment problem.
Our single agent implementation used its search tool to send separate queries about each frontier lab at the same time.
- 'OpenAI philosophical framework for AI safety and alignment'
- 'Anthropic philosophical framework for AI safety and alignment'
- 'Google DeepMind philosophical framework for AI safety and alignment’
The search tool returned results about all three labs in a single lengthy string. Our single agent reasoned about the results for all three frontier labs and called the search tool again, asking independent queries of each.
- 'DeepMind statements on social choice and political philosophy'
- 'Anthropic statements on technical alignment challenges'
- 'OpenAI technical reports on recursive reward modeling'
In each tool-call iteration, the single agent juggled context from three independent threads. This was wasteful from a token and latency perspective.
We don’t need tokens about OpenAI’s recursive reward modeling approach to help us generate our next query about DeepMind’s alignment philosophies. Another important observation was that a single agent handling multiple topics would naturally research each topic less deeply (# of search queries) before choosing to finish.
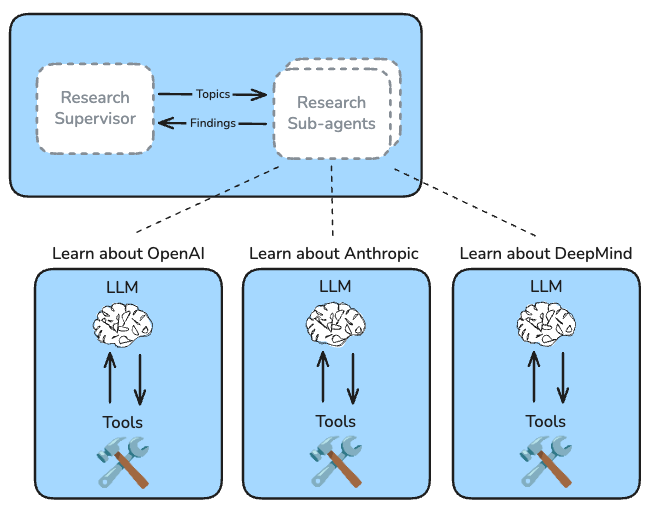
多智能体方法允许多个子智能体并行运行,每个子智能体都专注于一个独立、专注的任务。将多智能体方法应用于研究可以捕捉到 Anthropic 报告的益处,并在我们自己的评估中突出显示:每个子智能体中都可以隔离子主题上下文。
在研究过程中对子主题进行上下文隔离可以避免各种长上下文失效模式。
Multi-agent supervisor enables the system to tune to required research depth
多智能体监督者使系统能够调整到所需的研究深度
Users do not want simple requests to take 10+ minutes. But, there are some requests that require research with higher token utilization and latency, as Anthropic has nicely shown.
用户不希望简单的请求耗费 10 分钟以上。但是,有些请求需要更高 token 利用率和延迟的研究,正如 Anthropic 很好地展示的那样。
The supervisor can handle both cases by selectively spawning sub-agents to tune the level of research depth needed for a request. The supervisor is prompted with heuristics to reason about when research should be parallelized, and when a single thread of research is sufficient.
监督者可以通过选择性地生成子智能体来处理这两种情况,以调整请求所需的研究深度级别。监督者会根据启发式方法来推理何时应该并行化研究,以及何时单个研究线程就足够了。
Our deep research agent has the flexibility to choose whether to parallelize research or not.
我们的深度研究代理具有灵活性,可以选择是否并行化研究。
一个多智能体监督者允许搜索策略的灵活性。
Context Engineering is important to mitigate token bloat and steer behavior
上下文工程对于缓解 token 膨胀和引导行为非常重要。
Research is a token-heavy task. Anthropic reported that their multi-agent system used 15x more tokens than a typical chat application! We used context engineering to mitigate this.
研究是一项 token 密集型任务。Anthropic 报告称,他们的多智能体系统比典型的聊天应用多使用了 15 倍的 token!我们使用了上下文工程来缓解这一问题。
We compress the chat history into a research brief, which prevents token-bloat from prior messages. Sub-agents prune their research findings to remove irrelevant tokens and information before returning to the supervisor.
我们将聊天历史压缩成研究简报,这防止了先前的消息导致的 token 膨胀。子智能体在返回监督者之前,会修剪他们的研究成果以移除不相关的 token 和信息。
Without sufficient context engineering, our agent was prone to running into context window limits from long, raw tool-call results. Practically, it also helps save $ on token spend and helps avoid TPM model rate limits.
缺乏足够的上下文工程,我们的智能体容易因长而原始的工具调用结果而超出上下文窗口限制。实际上,这也有助于节省代币支出,并避免 TPM 模型速率限制。
上下文工程有许多实际好处。它节省代币,有助于避免上下文窗口限制,并有助于保持在模型速率限制之下。
Next Steps 下一步
Open deep research is a living project and we have several ideas we want to try. These are some of the open questions that we’re thinking about.
Open deep research 是一个持续发展的项目,我们有一些想法想要尝试。这些是我们正在思考的一些开放性问题。
- What is the best way to handle token-heavy tool responses, and what is the best way to filter out irrelevant context to reduce unnecessary token expenditure?
如何最佳处理包含大量 token 的工具响应,以及如何最佳过滤无关上下文以减少不必要的 token 消耗? - Are there any evaluations worth running in the hot path of the agent to ensure high quality responses?
在代理的热路径中,是否有值得运行的评价来确保高质量的响应? - Deep research reports are valuable and relatively expensive to create, can we store this work and leverage these in the future with long-term memory?
深度研究报告非常有价值且制作成本相对较高,我们能否将这些工作存储起来,并利用长期记忆在未来发挥作用?
Using Open Deep Research 使用 Open Deep Research
LangGraph Studio LangGraph 工作室
You can clone our LangGraph code and run Open Deep Research locally with LangGraph Studio. You can use Studio to test out the prompts and architecture and tailor them more specifically to your use cases!
您可以克隆我们的 LangGraph 代码,并使用 LangGraph Studio 在本地运行 Open Deep Research。您可以使用 Studio 来测试提示和架构,并根据您的具体用例进行更精确的定制!
Open Agent Platform 开放代理平台
We've hosted Open Deep Research on our demo instance of Open Agent Platform (OAP). OAP is a citizen developer platform, allowing users to build, prototype, and use agents - all you need to do is pass in your API keys. You can also deploy your own instance of OAP to host Deep Research alongside other LangGraph agents!
我们将 Open Deep Research 部署在我们的开放代理平台(OAP)演示实例上。OAP 是一个公民开发者平台,允许用户构建、原型设计和使用代理——您只需要提供 API 密钥即可。您还可以部署自己的 OAP 实例,以与其他 LangGraph 代理一起托管 Deep Research!