
Key Links 关键链接
Motivation 动机
Code generation and analysis are two of most important applications of LLMs, as shown by the ubiquity of products like GitHub co-pilot and popularity of projects like GPT-engineer. The recent AlphaCodium work showed that code generation can be improved by using a flow paradigm rather than a naive prompt:answer paradigm: answers can be iteratively constructed by (1) testing answers and (2) reflecting on the results of these tests in order to improve the solution.
代码生成和分析是 LLMs 最重要的应用之一,这一点从 GitHub co-pilot 等产品的普遍存在以及 GPT-engineer 等项目的流行中可以看出。最近的 AlphaCodium 工作表明,通过使用 flow 范式而不是简单的 prompt:answer 范式,可以改进代码生成:通过(1)测试答案和(2)反思这些测试的结果来迭代构建答案,从而改进解决方案。
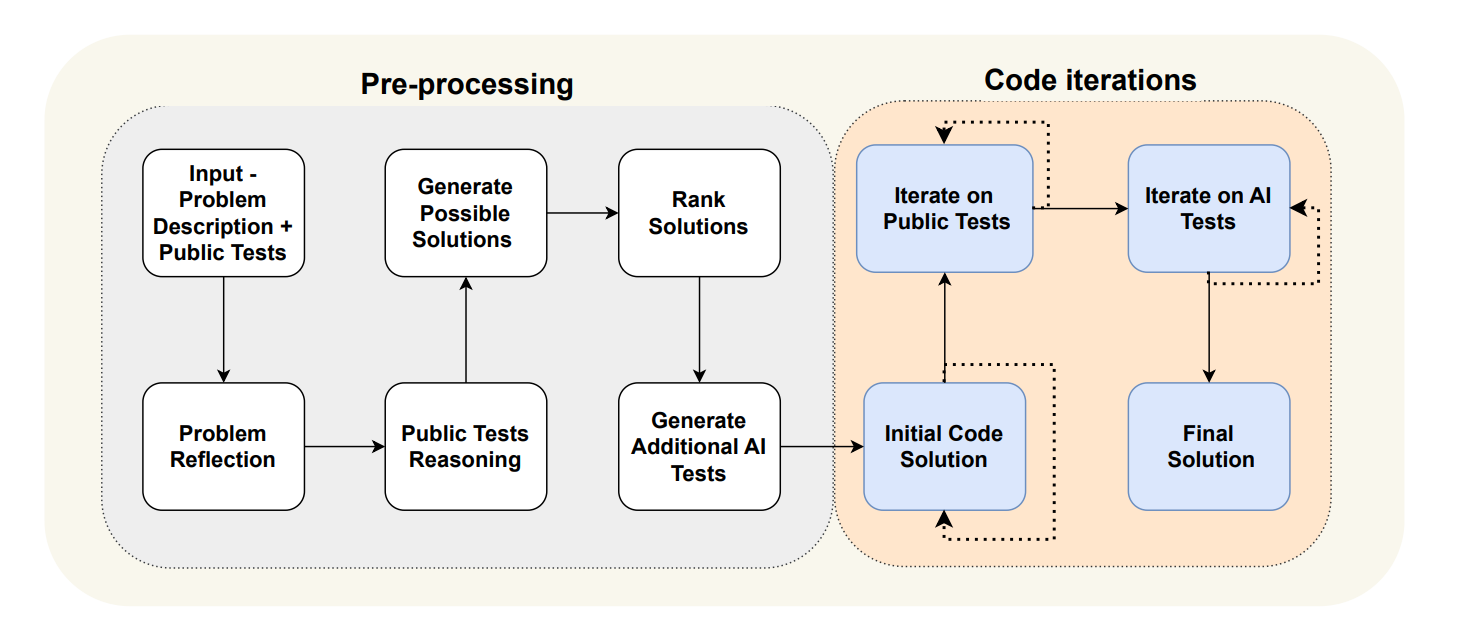
We recently launched LangGraph to support flow engineering, giving the user the ability to represent flows as a graph. Inspired by the AlphaCodium and Reflexion work, we wanted to demonstrate that LangGraph can be used to implement code generation with the same types of cycles and decisions points as shown above.
我们最近推出了 LangGraph 来支持流程工程,使用户能够将流程表示为图。受 AlphaCodium 和 Reflexion 工作的启发,我们想要证明 LangGraph 可以用来实现代码生成,其循环和决策点与上述所示相同。
Specifically we wanted to build and compare two different architectures:
具体来说,我们想要构建和比较两种不同的架构:
- Code generation via prompting and context stuffing
通过提示和上下文填充进行代码生成 - Code generation flow that involved checking and running the code, and then if there was some error passing it back to correct itself
涉及检查和运行代码的代码生成流程,如果有错误则将其反馈回去以自我修正
This would attempt to answer: how much can these code checks improve performance of a code generation system?
这将试图回答:这些代码检查能多大程度提高代码生成系统的性能?
The answer? 答案?
检查代码并尝试修复的系统,与单一代码生成的基线相比,取得了显著的改进(81% vs 55%)
Problem 问题
To demonstrate code generation on a narrow corpus of documentation, we chose a sub-set of LangChain docs focused on LangChain Expression Language (LCEL), which is both bounded (~60k token) and a topic of high interest. We mined 30 days of chat-langchain for LCEL related questions (code here). We filtered for those that mentioned LCEL, from >60k chats to ~500. We clustered the ~500 and had an LLM (GPT-4, 128k) summarize clusters to give us representative questions in each. We manually reviewed and generated a ground truth answer for each question (eval set of 20 questions here). We added this dataset to LangSmith.
为了在一个狭窄的文档语料库上展示代码生成,我们选择了 LangChain 文档中关于 LangChain 表达式语言(LCEL)的子集,该子集范围有限(约 60k 个 token),且是高兴趣主题。我们挖掘了 30 天的 chat-langchain 中关于 LCEL 的问题(代码在此)。我们从 >60k chats 到 ~500 中筛选出提及 LCEL 的问题。我们对约 500 个问题进行聚类,并使用 LLM(GPT-4,128k)对每个聚类进行总结,以给我们每个聚类中的代表性问题。我们手动审查并为每个问题生成一个真实答案(评估集包含 20 个问题,在此)。我们将这个数据集添加到了 LangSmith。
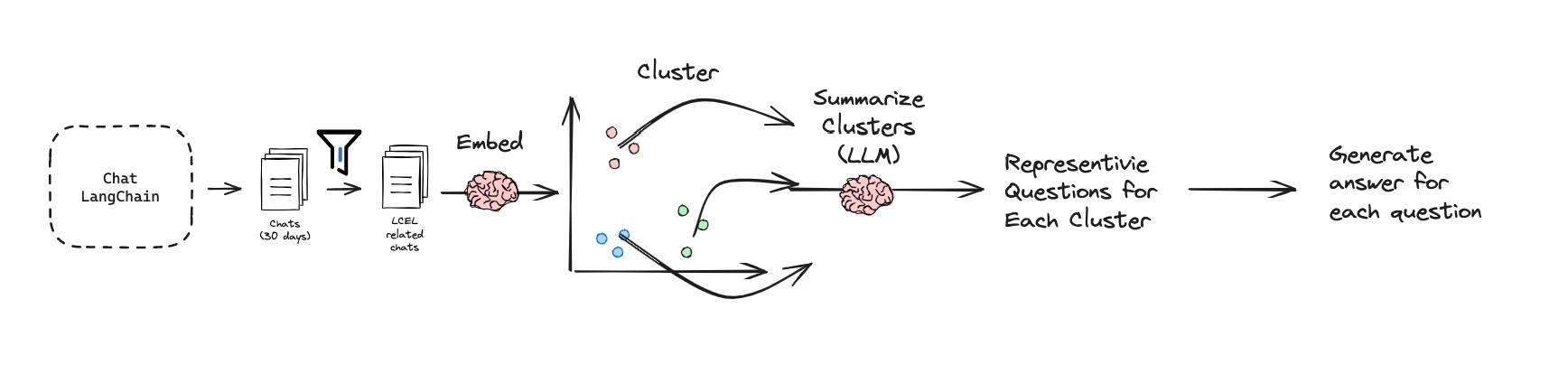
生成 LCEL 教师评估集的工作流程
Code generation with reflection using LangGraph
使用 LangGraph 进行反射的代码生成
We implement a code generation flow with the following components:
我们实现了一个包含以下组件的代码生成流程:
- Inspired by recent trends in long-context LLMs, we context stuff the 60k token LCEL docs using GPT-4 with a 128k token context window. We pass a question about LCEL to our context-stuffed LCEL chain for initial answer generation.
受近期长上下文 LLM 趋势的启发,我们使用具有 128k token 上下文窗口的 GPT-4 对 60k token 的 LCEL 文档进行上下文填充。我们将关于 LCEL 的问题传递给我们的上下文填充 LCEL 链,以进行初始答案生成。 - We use OpenAI tools to parse the output to a Pydantic object with three parts: (1) a preamble describing the problem, (2) the import block, (3) the code.
我们使用 OpenAI 工具将输出解析为一个包含三个部分的 Pydantic 对象:(1)描述问题的引言部分,(2)导入块,(3)代码。 - We first check import execution, because we have found that hallucinations can creep into import statements during code generation.
我们首先检查导入执行,因为我们发现幻觉会在代码生成过程中渗入导入语句。 - If the import check passes, we then check that the code itself can be executed. In the generation prompt, we instruct the LLM not to use pseudo-code or undefined variables in the code solution, which should yield executable code.
如果导入检查通过,我们接着检查代码本身是否可以执行。在生成提示中,我们指示 LLM 不要在代码解决方案中使用伪代码或未定义的变量,这应该能生成可执行的代码。 - Importantly, if either check fails, we pass back the stack trace along with the prior answer to the generation node to reflect We allow this to re-try 3 times (simply as a default value), but this can of course be extended as desired.
重要的是,如果任何一个检查失败,我们将堆栈跟踪连同之前的答案一起传递给生成节点,以反映这一点。我们允许它重试 3 次(仅仅作为默认值),但当然可以根据需要扩展。
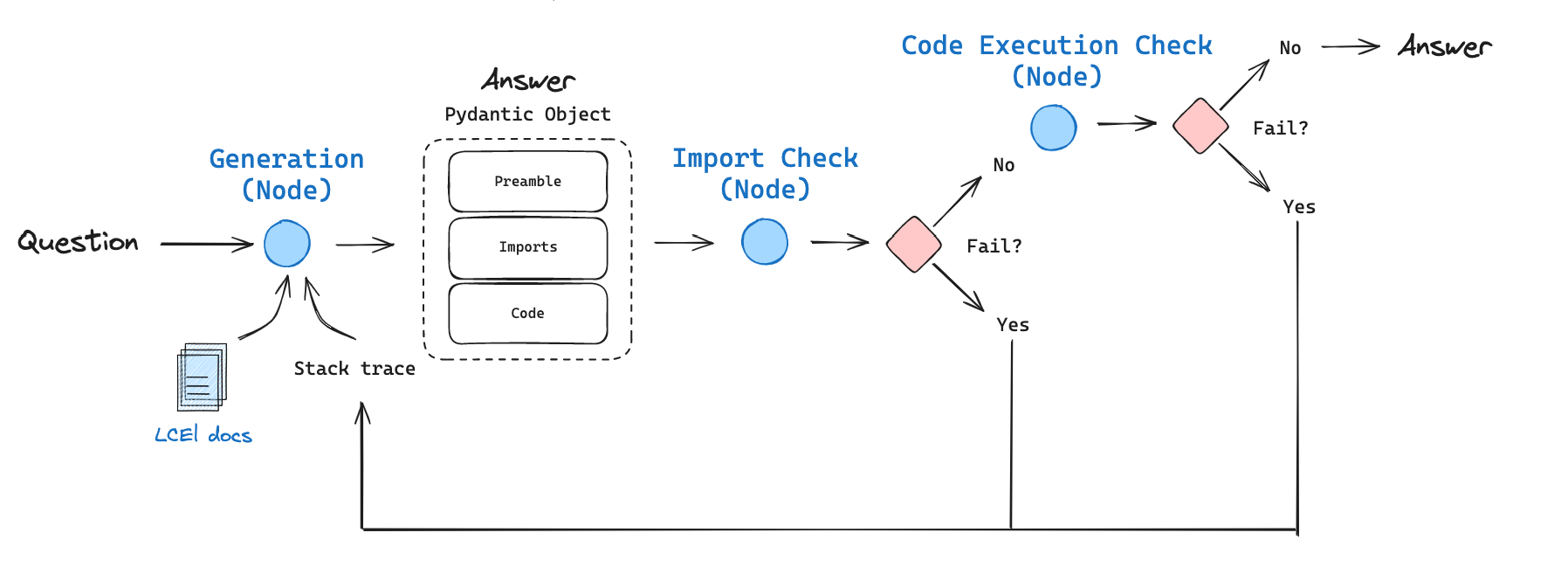
使用 LangGraph 进行代码执行,包含错误检查、反馈和反思
Evaluation with LangSmith
使用 LangSmith 进行评估
As a baseline, we implement context stuffing without LangGraph, which is the first node in our graph without any of the checks or feedback: we context stuff the 60k token LCEL docs using GPT-4 with a 128k token context window. We pass a question about LCEL to our context-stuffed LCEL chain for answer generation.
作为基线,我们未使用 LangGraph 实现了 context stuffing ,这是我们图中第一个没有任何检查或反馈的节点:我们使用具有 128k token 上下文窗口的 GPT-4 对 60k token 的 LCEL 文档进行上下文填充。我们将关于 LCEL 的问题传递给我们的上下文填充 LCEL 链以生成答案。
We implement LangSmith custom evaluators for both (1) import evaluation and (2) code execution. We run evaluation on context stuffing with our 20 question eval set four times. Here is our eval result. With context stuffing we see ~98% of the import tests are correct and ~55% of the code execution tests (N=79 successful trials). We use LangSmith to look at our failures: here is one example, which fails to see that the RunnableLambda function input will be a dict and thinks that it is a string: AttributeError: 'dict' object has no attribute 'upper'
我们为(1)导入评估和(2)代码执行实现了 LangSmith 自定义评估器。我们在 context stuffing 上使用我们的 20 题评估集进行了四次评估。以下是我们的评估结果。通过 context stuffing ,我们看到 ~98% 个导入测试是正确的,以及 ~55% 个代码执行测试( N=79 次成功尝试)。我们使用 LangSmith 查看我们的失败案例:这里有一个例子,它未能识别 RunnableLambda 函数输入将是 dict ,而认为它是 string : AttributeError: 'dict' object has no attribute 'upper'
We then tested context stuffing + LangGraph to (1) perform checks for errors like this in both imports and code execution and (2) reflect on any errors when performing updated answer generation. On the same eval set, we see 100% of the import tests are correct along with ~81% of the code execution tests (N=78 trials).
然后我们测试了 context stuffing + LangGraph ,以(1)检查导入和代码执行中的此类错误,以及(2)在执行更新答案生成时反思任何错误。在相同的评估集上,我们看到 100% 的导入测试是正确的,以及 ~81% 的代码执行测试( N=78 次试验)。
We can revisit the above failure to demonstrate why: the full trace shows that we do hit that same error here, in our second attempt at answering the question. We include this error in our reflection step in which both the prior solution and the resulting error are provided within the prompt for the final (correct) answer:
我们可以重新审视上述失败来解释原因:完整的调用栈显示,我们在第二次尝试回答问题时确实遇到了同样的错误。我们在反思步骤中包含了这个错误,在反思步骤中,先前的解决方案和最终产生的错误都被提供给了最终(正确的)答案的提示:
You previously tried to solve this problem.
...
--- Most recent run error ---
Execution error: 'dict' object has no attribute 'upper'
...
Please re-try to answer this.
...The final generation then correctly handles the input dict in the RunnableLambda function, bypassing the error observed in the context stuffing base case. Overall, adding this simple reflection step and re-try using LangGraph results in a substantial improvement on code execution, ~47% improvement:
最终生成正确处理了输入字典,在 RunnableLambda 函数中绕过了 context stuffing 基准情况中观察到的错误。总体而言,添加这个简单的反射步骤并重新使用 LangGraph,在代码执行上带来了显著改进, ~47% 改进:
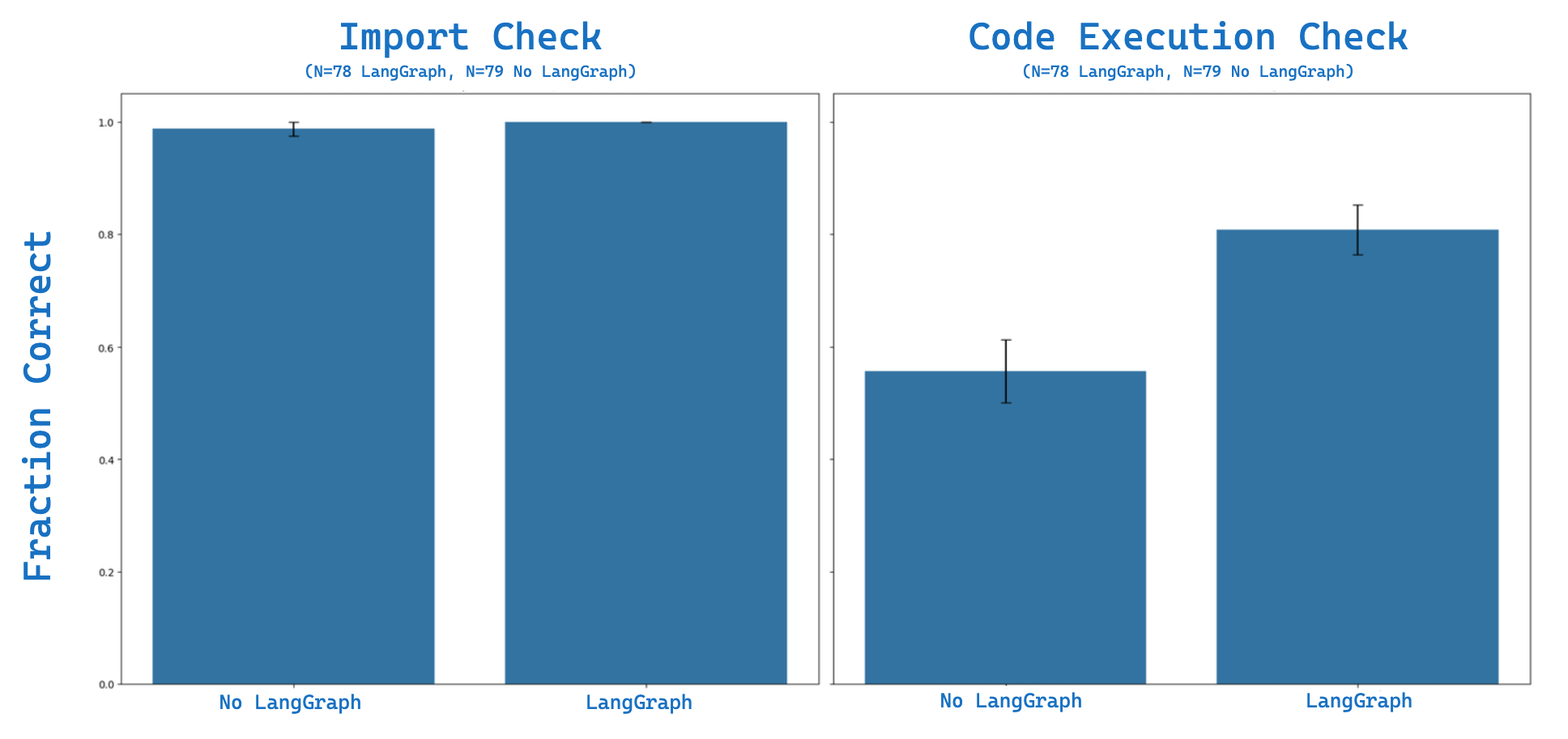
使用 LangGraph 和不使用 LangGraph 的导入和代码执行 LangSmith 评估
Conclusion 结论
LangGraph makes it easy to engineer flows with various cycles and decision points. Recent work has shown that this is powerful for code generation, where answers to coding questions can be constructed iteratively using using tests to check answers, reflect on failures, and iteratively improve the answer. We show that this can be implemented in LangGraph and test it on 20 questions related to LCEL for both code imports and execution. We find that context stuffing + LangGraph with reflection results in ~47% improvement in code execution relative context stuffing. The notebook is here and be extended to other codebases trivially.
LangGraph 可以轻松地设计包含各种循环和决策点的流程。近期研究表明,这在代码生成方面非常有效,可以通过测试来检查答案、反思失败,并迭代改进答案。我们展示了这种方法如何在 LangGraph 中实现,并在与 LCEL 相关的 20 个问题(涉及代码导入和执行)上进行了测试。我们发现,通过反思,代码执行效率提升了 ~47% 相对于 context stuffing 。相关笔记本在此,并且可以轻松扩展到其他代码库。