
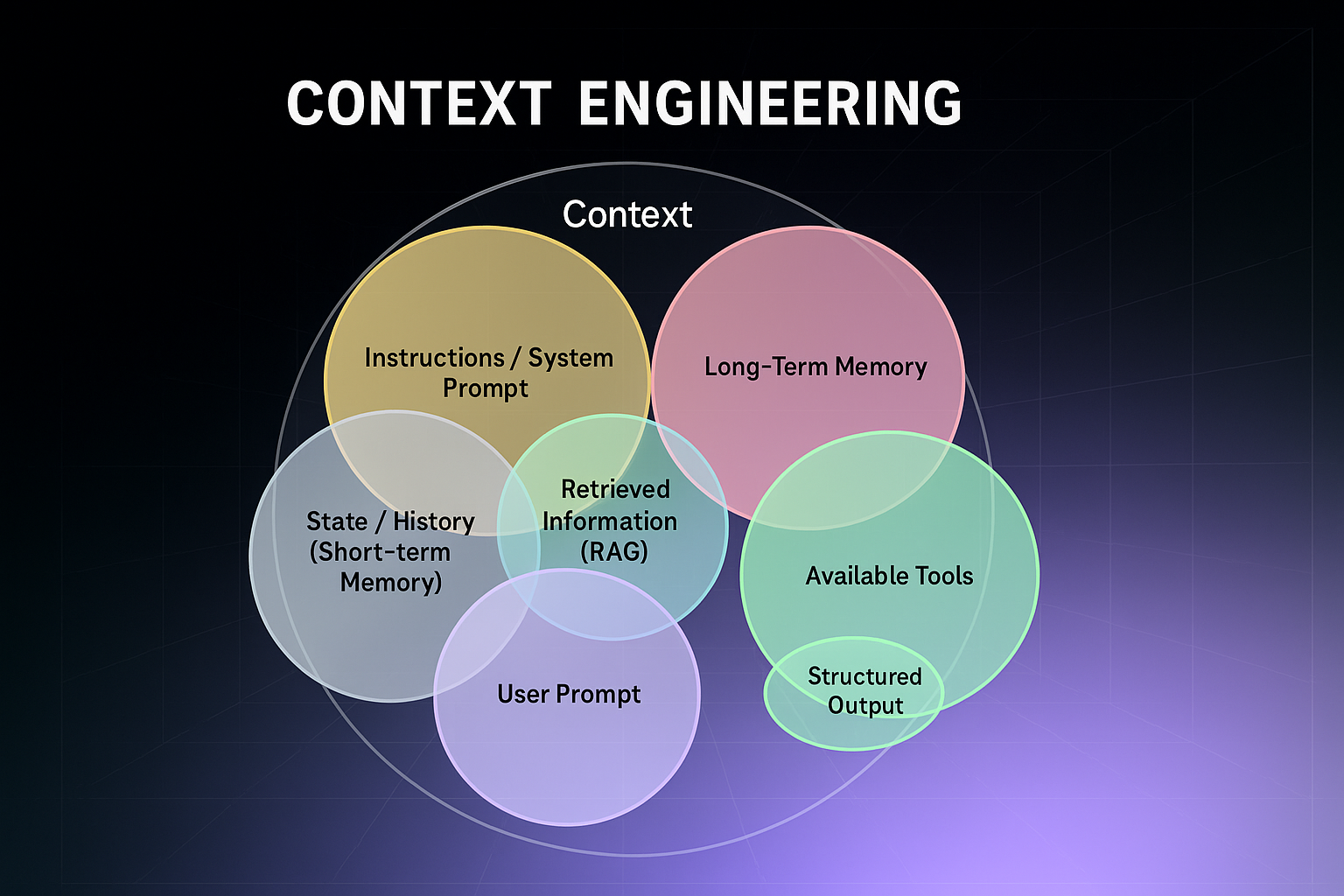
2025 年文档数据提取:LLMs 与 OCR 的对比
A choice dependent on specific needs, document types and business requirements.
一个取决于特定需求、文档类型和业务要求的选择。


For nearly two decades, Optical Character Recognition, OCR, was the predominant strategy for converting images or PDF documents into structured data. OCR had several commercial applications, including reading bank checks, processing scanned receipts, and verifying photographed IDs.
近二十年来,光学字符识别(OCR)一直是将图像或 PDF 文档转换为结构化数据的主要策略。OCR 具有多种商业应用,包括读取银行支票、处理扫描收据和验证照片身份证明。
But things are starting to change with LLMs.
但情况开始随着 LLMs 的变化而改变。
Many developers have switched from OCR to LLMs due to broader use cases, lower costs, and simpler implementation. We've seen this shift firsthand with many of our customers who were previously stuck with rigid OCR systems and are now amazed at how much easier LLMs work with unstructured data.
许多开发人员已从 OCR 转向 LLMs,这得益于更广泛的应用场景、更低的成本和更简单的实现方式。我们亲眼见证了这一转变,许多客户之前受困于僵化的 OCR 系统,现在对 LLMs 如何轻松处理非结构化数据感到惊叹。
For example, Gemini Flash 2.0 achieves near-perfect OCR accuracy while being incredibly affordable. It can successfully extract 6000 pages for just 1 dollar.
例如,Gemini Flash 2.0 实现了近乎完美的 OCR 准确率,同时价格极其实惠。它只需 1 美元就能成功提取 6000 页。
However, it's not a cut-and-dry replacement: OCR and LLMs have distinct advantages (and disadvantages). Depending on your data extraction needs, one (or both) might be the better option.
然而,这并非简单的替代关系:OCR 和 LLMs 各有独特的优势(和劣势)。根据您的数据提取需求,其中之一(或两者)可能是更好的选择。
Today, I'll dive into the differences, focusing on practical use cases for each, including instances where both might be appropriate.
今天,我将深入探讨两者的差异,重点关注每种技术的实际应用场景,包括两者都适用的情况。
OCR for Document Extraction
OCR 用于文档提取
Unlike LLMs, OCR's underlying mechanism is mostly deterministic. It follows a step-by-step process to recognize text in images.
与 LLMs 不同,OCR 的底层机制主要是确定性的。它遵循逐步过程来识别图像中的文本。

Because documents have text regions, tables, and images, with an OCR approach we first go through a layout analysis to break documents into these different sections, processing each section through specific recognition steps. This process cleans up the image by converting it to black and white (binarization), straightening it (deskewing), and removing spots or smudges (noise removal).
因为文档包含文本区域、表格和图像,使用 OCR 方法时,我们首先进行布局分析,将文档分解为这些不同部分,并通过特定的识别步骤处理每个部分。这个过程通过将其转换为黑白(二值化)、矫正(去倾斜)以及去除斑点或污渍(去噪)来清理图像。
Then, it identifies and separates each character in the image. Then finally, good OCR systems have a final quality control step that applies language rules to catch mistakes. For example, if the OCR reads "app1e" (with a number "1" instead of the letter "l"), it can correct it to "apple" by checking against a dictionary.
然后,它识别并分离图像中的每个字符。最后,良好的 OCR 系统有一个最终的质量控制步骤,应用语言规则来捕捉错误。例如,如果 OCR 读取"app1e"(数字"1"代替字母"l"),它可以通过对照字典将其更正为"apple"。
This structured approach is actually one of the biggest limitations of LLMs today, and what every model provider is working to solve.
这种结构化方法实际上是 LLMs 目前最大的局限性,也是所有模型提供方正在努力解决的问题。
While LLMs will extract ALL data, they don't "see" components and structure the same way OCR does, which can lead to problems. For instance, one of our customers was extracting data from resumes, and even the best models would mix the job descriptions between different positions.
虽然 LLMs 会提取所有数据,但它们不会像 OCR 那样"看到"组件和结构,这可能导致问题。例如,我们的一位客户正在从简历中提取数据,即使是最好的模型也会将不同职位的职位描述混在一起。
LLMs for Document Extraction
用于文档提取的 LLMs
Multimodal LLMs represent a completely different approach to document processing. Instead of treating extraction as a recognition problem (identifying individual characters), they approach it as a contextual task (understanding the document as a whole).
多模态 LLMs 代表了一种完全不同的文档处理方法。它们不是将提取视为识别问题(识别单个字符),而是将其视为上下文任务(将文档作为一个整体来理解)。

Models like GPT-4 Vision, Claude 3.7 Sonnet, and Gemini 2.5 Pro look at both text and images together, so they can understand the full document, not just isolated pieces of it. The approach is similar to how humans read documents. When you look at a bank statement, you don't just see individual characters, but you recognize it as a bank statement and understand what different sections mean based on your prior knowledge.
像 GPT-4 Vision、Claude 3.7 Sonnet 和 Gemini 2.5 Pro 这样的模型会同时分析文本和图像,因此它们能够理解整个文档,而不仅仅是其中的孤立部分。这种方法类似于人类阅读文档的方式。当你查看银行对账单时,你不会只看到单个字符,而是会将其识别为银行对账单,并根据你先前的知识理解不同部分的意思。
For instance, an LLM might recognize that a document is a bank statement and, applying its background knowledge of bank statements, easily create a table of transaction names, amounts, and dates.
例如,一个 LLM 可能会识别出一份文档是一份银行对账单,并利用其对银行对账单的背景知识,轻松创建一个包含交易名称、金额和日期的表格。
But how does it work — technically?
但它是如何运作的——从技术角度来看?
LLMs transform document images into what's called a "latent representation". Think of it as the model's internal understanding of the document. It's like how your brain doesn't store the exact pixels of a document you've seen but rather a conceptual understanding of what was in it:
LLMs 将文档图像转换为一种称为"潜在表示"的东西。可以将其视为模型对文档的内部理解。这就像你的大脑不会存储你看到的文档的确切像素,而是存储对其中内容的抽象理解一样:
It’s similar to how your brain doesn’t remember the exact pixels of a document. It remembers the meaning of what was there.
这与你大脑不记住文档的确切像素的方式类似。它记住的是那里内容的含义。

Below a preview of a Vellum workflow where we extract items from a menu, invoice and product spec CSV. If you want to try it out for your use-case, book a demo with one of our AI experts here.
以下是一个 Vellum 工作流程的预览,我们从菜单、发票和产品规格 CSV 文件中提取项目。如果您想针对您的用例尝试,请在此处预约我们的 AI 专家进行演示。
Now that we’ve gone over the key technical differences, let’s dig into how each one is used and what they’re good for.
在了解了关键技术差异后,让我们深入探讨每种技术的使用方式及其优势。
Application and Benefits 应用与优势
Simplicity 简单性
Multimodal LLMs significantly improve the developer experience from a time-to-deployment standpoint. Because LLMs are configured with prompts and don't require complex fine-tuning, they eliminate the need for structured inputs. This contrasts heavily with OCR that requires template creation and rule definition to extract content from documents accurately.
多模态 LLMs 在部署时间方面显著提升了开发者的体验。由于 LLMs 通过提示进行配置,且无需复杂的微调,因此它们消除了对结构化输入的需求。这与 OCR 形成了鲜明对比,OCR 需要创建模板和定义规则才能从文档中准确提取内容。
For example, extracting information from a medical record might require a prompt as simple as: "Extract the patient's name, patient ID, test ID, and result scores from this medical record."
例如,从医疗记录中提取信息可能只需要一个简单的提示:“从这份医疗记录中提取患者的姓名、患者 ID、测试 ID 和结果分数。”
This works even if the medical records have arbitrary formats. This strongly contrasts with OCR systems that would require defined file positions or templates for each document type.
即使医疗记录具有任意格式,这种方法也能正常工作。这与 OCR 系统形成鲜明对比,后者需要为每种文档类型定义文件位置或模板。
It’s very simple to use LLMs for data extraction. Just take a look at the preview of a Vellum workflow below, where we extract items from a menu, invoice and product spec CSV. If you want to try it out for your use-case, book a demo with one of our AI experts here.
使用 LLMs 进行数据提取非常简单。只需查看下方 Vellum 工作流的预览,我们就能从菜单、发票和产品规格 CSV 中提取项目。如果您想针对您的用例尝试,请在此处预约我们的 AI 专家进行演示。
Control 控制
LLMs do have a trade-off, however. OCR systems offer fine-grained control over each processing step. If the type of input is predictable, such as a static government form that never changes, then OCR would offer more control, enabling developers to extract only what is necessary.
LLMs 确实存在权衡。OCR 系统对每个处理步骤提供细粒度控制。如果输入类型可预测,例如永远不会改变的静态政府表格,那么 OCR 将提供更多控制,使开发者能够仅提取必要信息。
For example, developers could avoid extracting Social Security Numbers from W-9 forms by explicitly instructing the OCR which text box areas to process and which to ignore—something that's harder to guarantee with LLMs.
例如,开发者可以通过明确指示 OCR 处理哪些文本框区域并忽略哪些区域来避免从 W-9 表格中提取社会安全号码——而这一点用 LLMs 更难保证。
Accuracy 准确率
When it comes to accuracy, the key question is: can you count on the system to consistently extract data in the expected structure?
在准确率方面,关键问题是:你能依赖系统始终如一地按照预期结构提取数据吗?
OCR systems can hit 99% accuracy if documents are well-formatted with an unchanging layout—such as a 1099 form. Because these documents barely change, OCR's structured approach offers unbeatable reliability.
OCR 系统在文档格式良好且布局固定的情况下,如 1099 表格,可以达到 99%的准确率。由于这些文档几乎不会变化,OCR 的结构化方法提供了无与伦比的可靠性。
This advantage flips in LLMs' favor for documents with variable layouts and often poor quality. For example, Ramp, a finance automation platform, found that data extraction with LLMs dramatically improved their receipt processing accuracy.
这种优势在具有可变布局且通常质量较差的文档中更有利于 LLMs。例如,金融自动化平台 Ramp 发现,使用 LLMs 进行数据提取显著提高了他们的收据处理准确率。
Plus, according to recent benchmarks from Omni AI research, while OCR maintains an edge in pure character recognition for high-quality documents, LLMs increasingly outperform traditional systems in end-to-end extraction tasks that require understanding document structure and context.
此外,根据 Omni AI 最近的研究基准,虽然 OCR 在高质量文档的纯字符识别方面仍保持优势,但 LLMs 在需要理解文档结构和上下文的端到端提取任务中,正日益超越传统系统。

OmniAI 进行的评估结果
The Omni AI research highlights confirmed the stipulation that LLMs excel at extracting text content, but sometimes struggle with maintaining the correct structure.
Omni AI 研究的成果证实了 LLMs 在提取文本内容方面表现出色,但有时难以保持正确的结构。
This is exactly what happened with one of our customers who was processing thousands of resumes. The LLM would extract all the correct information but would sometimes associate job descriptions with the wrong positions.
这正是我们一位正在处理数千份简历的客户遇到的情况。LLM 会提取所有正确信息,但有时会将职位描述与错误的工作岗位关联起来。
Scalability 可扩展性
OCR systems scale linearly with computing resources. They can be easily parallelized across multiple servers for high-volume processing. LLM-based solutions, especially when using third-party APIs, may face rate limiting, concurrency restrictions, or unpredictable performance during peak usage periods.
OCR 系统随着计算资源线性扩展。它们可以轻松地在多台服务器上并行化,以进行高容量处理。基于 LLM 的解决方案,特别是使用第三方 API 时,在高峰使用期间可能会面临速率限制、并发限制或不稳定的性能。
Of course, you could deploy open-source LLMs on your own hardware, but that requires significant computational resources, particularly for the largest and most capable models.
当然,你可以在自己的硬件上部署开源 LLM,但这需要大量的计算资源,特别是对于最大和最强大的模型。
Cost Comparison 成本比较
Traditional OCR pricing typically involves an upfront license cost (or, if open-source, requires in-house development costs). The cost on a per-document basis is minimal. LLM-based extraction follows a usage-based pricing model where costs are determined by input and output tokens.
传统 OCR 定价通常涉及前期许可证费用(如果是开源的,则需要内部开发成本)。按文档计算的成本极低。基于 LLM 的提取采用按使用量计价的模式,成本由输入和输出 token 决定。
With LLMs, there's little upfront investment, but costs scale with volume. However, recent advancements have dramatically reduced these costs:
使用 LLMs,前期投入不大,但成本会随着使用量增加。然而,最近的进展已大幅降低了这些成本:

For example, Gemini Flash 2.0 can process 6000 pages for just $1, making it competitive with or cheaper than many traditional OCR solutions, especially when you factor in development and maintenance costs.
例如,Gemini Flash 2.0 可以处理 6000 页,只需 1 美元,使其在与许多传统 OCR 解决方案相比时具有竞争力或更便宜,特别是当你考虑到开发和维护成本时。
Here's a quick comparison:
这里有一个快速比较:
Latency comparison 延迟比较
OCR systems are very fast, able to process documents in milliseconds to a few seconds, depending on complexity. LLMs take at least a few seconds per document due to the computational intensity of neural networks.
OCR 系统非常快,能够以毫秒到几秒的时间处理文档,具体取决于复杂程度。LLMs 由于神经网络的计算强度,每处理一个文档至少需要几秒钟。

For applications that need to process documents for one-off steps (e.g., ID verification), this latency difference isn't an issue. However, for applications that need to import massive troves of documents to function, this latency can lead to significant delays.
对于需要一次性处理文档的应用(例如身份验证),这种延迟差异不是问题。然而,对于需要导入大量文档才能运行的应用,这种延迟可能导致显著延迟。
Failure modes 失效模式
OCR systems typically fail due to image quality issues. Low resolution, poor contrast, unusual fonts, and complex backgrounds consistently degrade performance. OCR also struggles with handwritten text, documents with non-standard layouts, and content that generally requires contextual interpretation to understand structure.
OCR 系统通常因图像质量问题而失败。低分辨率、对比度差、非标准字体和复杂的背景会持续降低性能。OCR 在处理手写文本、非标准布局的文档以及需要上下文解释才能理解结构的內容时也难以应对。
LLM failure modes are less tied to the document and more to the prompts used. A malformed prompt can lead itself to hallucination. LLMs generally seek to "satisfy" the user's prompt, even if it involves conjuring information to do so.
LLM 的失效模式与文档本身关系不大,更多与所使用的提示有关。一个格式错误的提示可能导致幻觉。LLM 通常试图“满足”用户的提示,即使这意味着凭空捏造信息。
The reliability implications of these failure modes are distinct. OCR errors tend to be obvious and consistent (weirdly formatted data, missing text, or uncommon unicode characters). LLMs meanwhile produce data that looks right, despite not correctly representing the structure.
这些失效模式带来的可靠性影响是不同的。OCR 错误往往显而易见且一致(格式奇怪的数据、缺失文本或不常见的 Unicode 字符)。而 LLM 则产生看似正确的数据,尽管它未能正确表示结构。
When to Use OCR, LLMs, or Both
何时使用 OCR、LLMs 或两者结合
We've seen firsthand how different document types benefit from different approaches. For example, one of our financial services customers processes thousands of W-9 forms daily and gets the best results from a traditional OCR approach with validation rules.
我们亲眼见证了不同文档类型如何从不同方法中受益。例如,我们一家金融服务客户每天处理数千份 W-9 表格,并从带有验证规则的传统 OCR 方法中获得最佳结果。
Conclusion 结论
The choice between OCR and LLMs for document extraction isn't binary, it depends on your specific needs, document types, and requirements.
选择 OCR 和 LLMs 进行文档提取并非非此即彼的选择,这取决于您的具体需求、文档类型和需求。
LLMs represent the optimal choice for document extraction projects with:
对于具有以下特征的文档提取项目,LLMs 是最佳选择:
- Documents with variable or unpredictable layouts
具有可变或不规则布局的文档 - Tasks requiring contextual understanding or inference
需要上下文理解或推理的任务 - Projects with rapid development timelines
具有快速开发时间表的项目 - Applications processing moderate document volumes
处理中等文档量的应用 - Extraction requirements that frequently change or evolve
频繁变化或演变的提取需求
Traditional OCR remains superior for scenarios with:
传统 OCR 在以下场景中仍然更优越:
- High-volume document processing where per-document LLM costs would be prohibitive
高容量文档处理,其中每份文档的 LLM 成本过高 - Applications with strict latency requirements
具有严格延迟要求的应用程序 - Documents with consistent layouts
布局一致的文档 - Environments with limited connectivity or strict data privacy requirements
连接受限或数据隐私要求严格的环境 - Extraction tasks focused on text recognition rather than contextual understanding
以文本识别而非上下文理解为焦点的提取任务
And for many real-world applications, a hybrid approach offers the best of both worlds.
对于许多实际应用来说,混合方法能兼顾两者的优点。
At Vellum, we've helped dozens of companies navigate this decision and implement the right solution for their specific needs. The most important thing is to start with a clear understanding of your document types, extraction requirements, and business constraints, then choose the technology that best addresses those specific needs.
在 Vellum,我们已帮助数十家公司做出这一决策,并为他们特定的需求实施合适的解决方案。最重要的是,首先要明确理解文档类型、提取需求和业务限制,然后选择最能满足这些特定需求的技术。
If you want to learn more — book a call with one of our AI experts here.
如果您想了解更多——请在此处预约一位我们的人工智能专家进行通话。

.png)
.png)
.png)
最佳 AI 技巧——直接发送至您的收件箱
Latest AI news, tips, and techniques
最新的 AI 新闻、技巧和技术
Specific tips for Your AI use cases
针对您的 AI 使用场景的具体建议
No spam 没有垃圾信息
Each issue is packed with valuable resources, tools, and insights that help us stay ahead in AI development. We've discovered strategies and frameworks that boosted our efficiency by 30%, making it a must-read for anyone in the field.
每期都包含宝贵的资源、工具和见解,帮助我们保持 AI 开发的领先地位。我们发现了能将效率提升 30%的策略和框架,使其成为该领域任何人必读的内容。
This is just a great newsletter. The content is so helpful, even when I’m busy I read them.
这只是一份很棒的简报。内容非常实用,即使我很忙也会阅读。

Experiment, Evaluate, Deploy, Repeat.
实验、评估、部署、重复。
AI development doesn’t end once you've defined your system. Learn how Vellum helps you manage the entire AI development lifecycle.